

Jak stworzyć własny linter w Pythonie?
Cześć!
Na początek muszę przyznać się do czegoś, mianowicie… wiosna oderwała mnie od komputera. To sprawiło, że mniej nowych rzeczy pojawia się zarówno na blogu jak i w social mediach. Musicie mi to jakoś wybaczyć. Na szczęście „mniej” nie znaczy „w ogóle”, więc dziś zapraszam na artykuł w którym zbudujemy własny linter.
Czym jest linter?
Linter to aplikacja do statycznej analizy kodu. Historycznie słowo „lint” odnosiło się do programu pomagającego wykryć błędy, analizującego kod napisany w C pod kątem podejrzanych lub nieprzenośnych instrukcji. Nazwa jak i przeznaczenie się nie zmieniły, a sama idea rozprzestrzeniła się praktycznie na wszystkie języki.
Coraz częściej lintery bywają wbudowywane w IDE i na bieżąco pokazują nam ewentualne problemy z naszym kodem. Mimo to, samodzielne programy tego typu nadal mają się bardzo dobrze i często możemy spotkać się z nimi w procesach CI/CD – są one dla programistów jednym z narzędzi, które stoją na straży jakości tworzonego kodu.
Linter nie jest jednak magicznym rozwiązaniem pozwalającym utrzymywać kod w dobrej kondycji. Nie można oczywiście zaprzeczyć, że pomaga wyłapywać błędy czy utrzymywać standardy kodowania, ale trzeba pamiętać, że jest to nadal statyczna analiza kodu i nie zastąpi ona w żadnym stopniu doświadczenia programistów.
Lintery w Pythonie
W ekosystemie Pythona najpopularniejszym linterem jest oczywiście PyLint. Pozwala on, jak większość tego typu programów, na konfigurację zarówno dodającą nowe funkcjonalności jak i ustawienia ograniczające lub zmieniające domyślne reguły. Poza PyLintem jest jeszcze Flake8, a także narzędzia, które mogą nasz kod automatycznie poprawić jak np. Black.
Reguły lintera to zbiór zasad pod kątem których linter sprawdza nasz kod. Dla przykładu:
- ilość znaków w każdej linii,
- długość nazw zmiennych,
- długość nazw funkcji,
- wielkość znaków,
- odstępy między kolejnymi blokami kodu,
- ilość argumentów do funkcji,
- długość funkcji,
- ilość słów „return” w funkcji,
- itp..
Czekaj, stop!
Podoba Ci się to co tworzę? Jeśli tak to zapraszam Cię do zapisania się na newsletter:Jeśli to Cię interesuje to zapraszam również na swoje social media.
Jak i do ewentualnego postawienia mi kawy :)

Jak działa linter?
Wspomniany wcześniej przeze mnie PyLint używa pod spodem pakietu ast, który dostarcza narzędzia pozwalające na budowę abstrakcyjnego drzewa składniowego (ang. abstract syntax tree). Takie drzewo jest wynikiem analizy składniowej robionej wg konkretnej gramatyki. Więcej informacji o gramatykach, jak i o samym podejściu do tworzenia języków programowania, możesz przeczytać w tym artykule. Każdy węzeł wewnętrzny takiego drzewa reprezentuje pewną konstrukcję języka, a jego synowie znaczące składowe tej konstrukcji. Zobaczmy to na przykładzie!
Uruchamiając taki kod:
1 2 3 4 5 6 7 8 9 | import ast code = """ test = 20 """ tree = ast.parse(code) print(ast.dump(tree, indent=4)) |
dostaniemy:
Module(
body=[
Assign(
targets=[
Name(id='test', ctx=Store())],
value=Constant(value=20))],
type_ignores=[])
To, na co patrzymy, to właściwie już nasze drzewo składniowe. Określa ono elementy z których składa się kod, który analizowaliśmy. Idąc od góry napotykamy na moduł. Moduł składa się z body, czyli ciała modułu. Nasze body składa się z komponentu Assign, czyli przypisania. Atrybut targets wskazuje na cel i j jest nim komponent Name o id „test” czyli po prostu nasza zmienna. Atrybut value wskazuje co zostanie przypisane czyli stała „20”. Proste, prawda? Tak mogłoby to wyglądać, gdybyś chcieli zrobić graficzną reprezentację takiego drzewa:
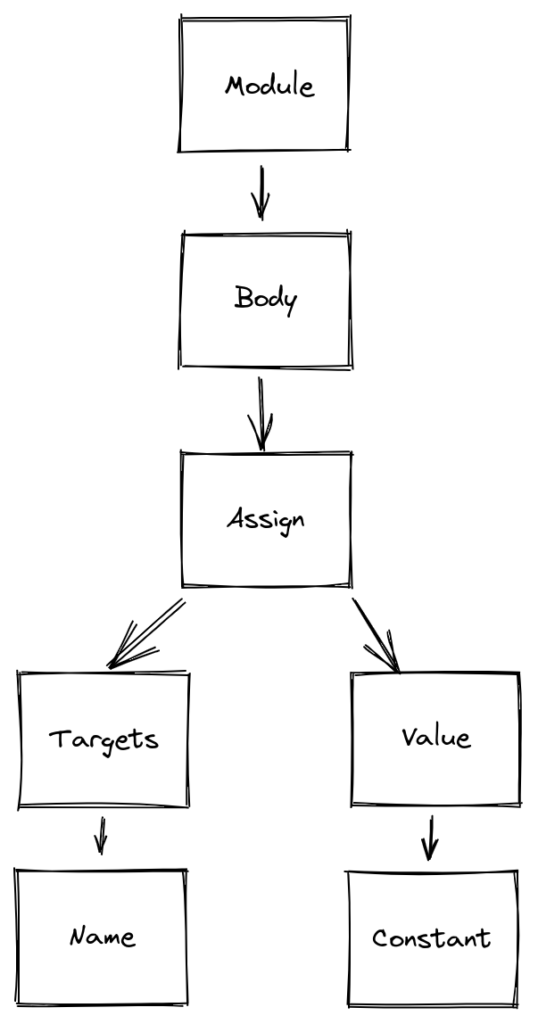
To zobaczmy coś bardziej skomplikowanego:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import ast code = """ number = 20 if number > 10: print(number) else: print(number - 10) """ tree = ast.parse(code) print(ast.dump(tree, indent=4)) |
i jego ast:
Module(
body=[
Assign(
targets=[
Name(id='number', ctx=Store())],
value=Constant(value=20)),
If(
test=Compare(
left=Name(id='number', ctx=Load()),
ops=[
Gt()],
comparators=[
Constant(value=10)]),
body=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
Name(id='number', ctx=Load())],
keywords=[]))],
orelse=[
Expr(
value=Call(
func=Name(id='print', ctx=Load()),
args=[
BinOp(
left=Name(id='number', ctx=Load()),
op=Sub(),
right=Constant(value=10))],
keywords=[]))])],
type_ignores=[])
Początek jest prosty. Przypisujemy stałą 20 do zmiennej number. Potem znajdziemy komponent IF, który zawiera test, gdzie lewym operandem jest zmienna number. Następnie w atrybucie „ops” mamy wskazany operator, czyli w tym przypadku Gt() czyli „grater than” i atrybut comparators, czyli elementy do których porównujemy – w tym przypadku do stałej 10. Dalej w naszym drzewie jest ciało (to pod IFem) w którym mamy wyrażenie (Expr) z wartością wywołania funkcji (Call) z atrybutem func, wskazującym na nazwę funkcji i args z argumentami. Następnie jest komponent orelse, realizujący else’a w którym mamy bliźniaczo podobne wywołanie funkcji co wcześniej, z tą różnicą, że tu jako argument nie mamy stałej, ale komponent BinOp, czyli operator binarny zdefiniowany atrybutem „op” jako Sub(), określający subtraction, czyli odejmowanie.
Atrybut ctx określa, co ma się zadziać z daną nazwą, czy ma zastać zapisana (np przy przypisaniu) czy załadowana (np. przy porównywaniu). Może jeszcze być usunięta, np. przy usuwaniu.
Myślę, że budowa tych drzew jest dość intuicyjna.
Napiszmy własny linter!
Jak się pewnie domyślasz, podobnie jak autorzy PyLinta, tak i my użyjemy pakietu ast do zbudowania naszego własnego lintera. Zanim jednak zaczniemy go tworzyć, pokażę w jaki sposób możemy np. wypisać wszystkie nazwy zmiennych użyte w przypisaniach w kodzie analizowanego programu.
W skrócie, trzeba stworzyć klasę dziedziczącą po ast.NodeVisitor i przeciążyć odpowiednią metodę. Kod mógłby wyglądać tak:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import ast from typing import List code = """ number = 20 second_number = number + 10 """ tree = ast.parse(code) class Visitor(ast.NodeVisitor): def visit_Assign(self, node: ast.Assign): targets: List[ast.Name] = node.targets print([x.id for x in targets]) Visitor().visit(tree) |
wypisze on nam:
['number'] ['second_number']
Jak widać, metody, które powinieneś przeciążyć mają dość sugestywne nazwy, trudno jest je pomylić. Jeśli nie jest się pewnym, można zerknąć do dokumentacji, gdzie każda z metod (a jest ich trochę) jest opisana.
A teraz coś trudniejszego! Napiszmy program, który wypisze ile przypisań jest w każdej zdefiniowanej funkcji. Kod mógłby wyglądać tak:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | import ast from typing import List code = """ def func(): first_var = 1 second_var = 2 third_var = 3 return first_var + third_var - second_var def func2(): first_var = 1 first_var = 2 return first_var def func3(): one, two, three, four = 1, 2, 3, 4 five, six = 5, 6 return first_var """ tree = ast.parse(code) class Visitor(ast.NodeVisitor): def visit_FunctionDef(self, node: ast.FunctionDef): statements: List[ast.stmt] = node.body assignments = [x for x in statements if isinstance(x, ast.Assign)] print(f"Func '{node.name}' has {len(assignments)} assignments.") Visitor().visit(tree) |
A wynikiem byłoby:
Func 'func' has 3 assignments. Func 'func2' has 2 assignments. Func 'func3' has 2 assignments.
Zauważ, że mimo, że w func3 stworzyliśmy aż 6 zmiennych, to przypisania są dwa. Jest to jak najbardziej poprawne.
Teraz już naprawdę piszemy własny linter
Żeby to się udało, potrzebujemy nieco abstrakcji. Stwórzmy pakiet o nazwie linter z modułami jak poniżej:
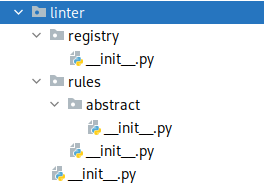
W pliku __init__.py modułu registry stworzymy klasę przechowującą reguły lintera. Może ona wyglądać tak:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | from collections import defaultdict from typing import List, Dict from linter.rules.abstract import Rule class Registry: def __init__(self): self._checkers: Dict[str, List[Rule]] = defaultdict(lambda: []) def add_checker(self, node_name: str, _class: Rule) -> None: self._checkers[node_name].append(_class) def get_checkers(self, node_name: str) -> List[Rule]: return self._checkers[node_name] registry = Registry() |
Czyli bez udziwnień – zbieramy klasy typu Rule w słowniku. Już w tym miejscu dajemy możliwość wielu reguł dla jednego typu komponentu.
Plik __init__.py dla rules.abstract zawierać będzie klasę abstrakcyjną (i logger, który raczej nie powinien dla kodu produkcyjnego się znajdować w tym miejscu):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | import abc import ast import logging class ContextFilter(logging.Filter): def __init__(self, lint_code: str, name: str = ''): super().__init__(name) self.lint_code = lint_code def filter(self, record): record.lint_code = self.lint_code return True class Rule: NODE: ast.stmt LINT_CODE: str = '' def __init__(self): self.log = logging.getLogger() custom_filter = ContextFilter(self.LINT_CODE) self.log.addFilter(custom_filter) logging.basicConfig(format='%(asctime)-15s %(levelname)-8s %(lint_code)-5s: %(message)s') @abc.abstractmethod def run(self, node: ast.stmt): pass |
Każda klasa będąca regułą lintera będzie musiała dziedziczyć po tej klasie, a więc implementować metodę run. Dodatkowo, każda klasa będzie definiowała pola NODE i LINT_CODE. Ten pierwszy to po prostu komponent z pakietu ast, którego reguła będzie dotyczyć. Jak wiele linterów, tak i nasz będzie posiadał kody reguł i za to właśnie odpowiadać będzie to drugie pole. Jest to prosty sposób określający z której reguły leci konkretny komunikat.
Został nam jeszcze plik „główny” czyli __init__.py dla samego pakietu linter. Może on wyglądać tak:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | import ast from typing import List, Any from linter.registry import registry from linter.rules.abstract import Rule class Visitor(ast.NodeVisitor): def generic_visit(self, node: ast.stmt) -> Any: checkers: List[Rule.__class__] = registry.get_checkers(type(node)) for checker in checkers: checker().run(node) super().generic_visit(node) class Linter: def __init__(self): self.visitor: Visitor = Visitor() def add_rule(self, rule: Rule.__class__): if not hasattr(rule, 'NODE'): raise RuntimeError("Checker should have NODE attr") registry.add_checker(rule.NODE, rule) def run_linter(self, code: str): self.visitor.visit(ast.parse(code)) |
Użyłem w Visitorze metody generic_visit która jest odpalana po prostu dla każdego komponentu drzewa. To pozwoliło mi nie definiować każdej metody, a po prostu, w określeniu o typ komponentu, pobrać odpowiednie klasy reguł i je wykonać.
Klasa Linter to taki publiczny interfejs dla naszego kodziku.
Użyjmy naszego lintera
Stwórzmy klasę reguły, która będzie podnosić „alarm” jeśli znajdzie w przypisaniu zmienną, której nazwa jest krótsza niż 5 znaków:
1 2 3 4 5 6 7 8 9 | class VariableNamesLengthRule(abstract.Rule): NODE: ast.stmt = ast.Assign LINT_CODE = 'Py123' def run(self, node: ast.Assign): names: List[ast.Name] = node.targets for name in names: if len(name.id) < 5: self.log.warning("Name %r is to short! Please be more verbose. ", name.id) |
I uruchommy nasz linter:
1 2 3 4 5 6 7 8 | code = """ test = 5 test2 = test + 4 """ linter: Linter = Linter() linter.add_rule(VariableNamesLengthRule) linter.run_linter(code) |
który poprawnie podniesie nam alarm:
2022-05-10 21:25:04,897 WARNING Py123: Name 'test’ is to short! Please be more verbose.
Oczywiście nasz linter to bardzo prosty kodzik i żeby nadawał się do profesjonalnych zastosowań, to trzeba by było spędzić przy nim jeszcze dużo czasu. Niemniej jednak, pokazuje on jak wykorzystać pakiet ast do analizy składni. Jestem prawie pewien, że już czujesz jaki potencjał w tym drzemie!
Wrzuciłem ten kod do repozytorium, tutaj link.
Zmierzając do końca
O tym, że ten wpis powstawał dość długo napisałem już na początku. W tym czasie kilkukrotnie zmieniał swój zakres. Pierwsza wersja była podobna do tego co właśnie przeczytałaś/eś, ale rozwiązanie było trochę bardziej magiczne, oparte o samorejestrujące się reguły (zaimplementowane metaklasą). Jednak im dłużej na ten kod patrzyłem, tym bardziej dochodziłem do wniosku, że jest on zbyt skomplikowany i zaciemni odbiór głównego tematu – czyli drzew abstrakcyjnych i pakietu ast. Uprościłem to rozwiązanie, ale rozszerzyłem zakres o modyfikację komponentów, bo pakiet ast, poza budowaniem drzewa i podróżowaniem po nim, pozwala też na jego modyfikację. Tu znów napotkałem problem: statystyki wskazują, że długie artykuły rzadko są czytane. Więc, żeby uniknąć sytuacji, w której z powodu długości tekstu moja praca pójdzie na marne, ponownie zawęziłem zakres.
Podobne dylematy mam praktycznie przy każdym artykule. I zawsze jest to samo balansowanie – przekazać na tyle dużo, żeby treść była wartościowa i na tyle mało, żeby dało się to pojąć. Wydaje mi się, że idzie mi nieźle, a jak Ty sądzisz?
Cieszę się, że udało mi się dokończyć ten artykuł. Mam nadzieję, że był on dla Ciebie wartościowy. Daj znać w komentarzu co sądzisz o pakiecie ast i możliwościach jakie on daje. Może jednak chcielibyście przeczytać więcej o tym zagadnieniu?
Mateusz Mazurek



Trochę to skomplikowane dla nowicjusza. Wrócę to za jakiś czas.