

Czym jest pozorna duplikacja kodu?
Cześć.
Artykuł ten jest efektem pracy nad jednym z projektów. Prawdę mówiąc, to mało pracuję czynnie nad tym projektem, bardziej jestem takim „dobrym duchem” pilnującym zakresu, wyboru rozwiązań, terminów no i ogólnie magicznie sprawiam, że całość „jakoś się toczy”. Projekt został zdekomponowany na mniejsze taski, tak by można było śledzić postęp. Przy jednym z tasków, omawiając już prawie gotowe rozwiązanie, natknąłem się na coś co nazwałem „pozorną duplikacją kodu”.
Co tam zobaczyłem?
Zacząłem pisać ten akapit, po prostu opisując, na co się natknąłem. Po chwili doszedłem do wniosku, że aby czytający mógł zrozumieć problem, potrzebowałby znacznie większej wiedzy domenowej, której nie jestem w stanie tu zamieścić. Posłużę się więc analogicznym przykładem.
Mamy jakiś system. W nim mamy użytkownika. Użytkownik ma 3 ustawienia możliwe do konfiguracji:
- maksymalny czas pracy w trybie A
- maksymalny czas pracy w trybie B
- maksymalny czas pracy w trybie C
Na tym etapie rozwoju tego softu, te trzy wartości są w ten sam sposób przetwarzane, ale wynik każdej z nich oddziałuje na inny element systemu. To co zobaczyłem, to właśnie funkcję, która bierze te trzy, przypadkiem podobne do siebie obliczenia, wrzucone w jedną funkcję. I zdziwienie na twarzy autora, kiedy dopytywałem o powód powstania takiego kodu.
Wejdźmy głębiej
Mamy trzy niezwiązane ze sobą ustawienia. Te trzy wartości w żaden sposób, w domenie rozwiązywanego problemu, nie spotykają się ze sobą. Mamy więc od strony kodu taką sytuację:
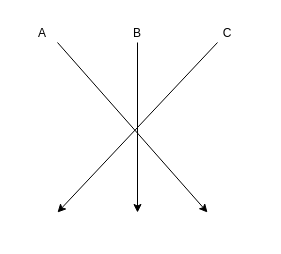
Natomiast, ta sama sytuacja, od strony domeny, wygląda tak:
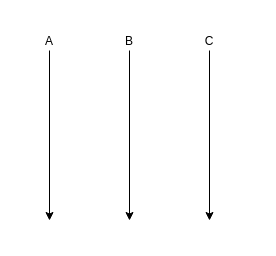
Co powinniśmy zrobić?
Możemy zrobić to co zaproponował autor, czyli tę duplikację uwspólnić, tworząc jeden komponent (obojętnie czy to funkcja, klasa czy cokolwiek innego) który będzie realizował tę funkcję. Jakie mamy konsekwencje takiej decyzji?
Przede wszystkim jedną ogromną – jeśli przyjdzie wymaganie, by zmienić działanie jednej ze ścieżek, to mamy problem. Bo to ta sama ścieżka! To jest sytuacja kiedy właśnie tworzone są bardzo brzydkie IFy, które wymuszają na komponencie, który miał mieć jedno zadanie, obsługę kolejnego zadania.
Drugim podejściem jest odwzorowanie kodu, tak by pasował do domeny. Spowoduje to powstanie duplikacji w kodzie. To co ważne jest to to, że to jest pozorna duplikacja. To że kod wygląda tak samo nie znaczy, że to ten sam kod.
Jak odróżnić duplikację pozorną od faktycznej?
Kod który piszemy to zapis założeń. Duplikacja faktyczna występuje wtedy kiedy duplikujemy implementację tych samych założeń. Z duplikacją pozorna mamy do czynienia, kiedy kod tylko przypadkiem wygląda podobnie a w rzeczywistości jest zapisem różnych założeń. W sytuacji kiedy z wielu miejsc, możemy wykonać tę samą operację i ma ona dać ten sam efekt to produkowanie kopii tej operacji jest błędem. Czasem się zdarza, że ciężko określić co jest czym – tutaj z pomocą może przyjść rozmowa z biznesem.
A i pytanie pomocnicze: Czy istnieje tylko jeden powód do zmiany tego kodu?
Załóżmy, że masz 3 bloki kodu. Wygląda on tak samo/bardzo podobne. Ile może istnieć powodów zmiany tego kodu? Jeśli jeden (np. wymaganie „dodawajmy do obrazków znak wodny”) to jest to ten sam kod. Jeśli natomiast kod może zmienić się w wyniku wielu dróg, to prawdopodobnie jest to pozorna duplikacja.
Czekaj, stop!
Podoba Ci się to co tworzę? Jeśli tak to zapraszam Cię do zapisania się na newsletter:Jeśli to Cię interesuje to zapraszam również na swoje social media.
Jak i do ewentualnego postawienia mi kawy :)

Pułapka słów „prawdopodobnie” i „bardzo podobne”
Oba te słowa padły we wcześniejszym rozdziale. Problem z nimi jest taki, że nie istnieje odgórnie narzucona ilości różnic, której przekroczenie, jednoznacznie określi, że to już jest inny komponent. Jest to dość umowne i raczej zależy od kontekstu, planów na rozwój aplikacji czy po prostu architektury systemu. Nie musimy też od razu robić kopiuj-wklej. Mamy do dyspozycji programowanie obiektowe, wstrzykiwanie zależności czy wzorce projektowe, takie jak fasada czy strategia, które pomogą nam uzyskać kod odporny na różnice i ewentualne zmiany.
Czy IDE umie nam pomóc?
Przyjrzyj się poniższemu kawałkowi kodu:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | from typing import List def shift_digits_to_right(words: List[str]) -> List[str]: processed = [] for word in words: digits = [] others = [] for letter in word: if letter.isdigit(): digits.append(letter) else: others.append(letter) processed.append(''.join(others + digits)) return processed print(shift_digits_to_right(['1a1a1a', '2z2z2z'])) def shift_digits_to_left(words: List[str]) -> List[str]: processed = [] for word in words: digits = [] others = [] for letter in word: if letter.isdigit(): digits.append(letter) else: others.append(letter) processed.append(''.join(digits + others)) return processed print(shift_digits_to_left(['1a1a1a', '2z2z2z'])) |
Jego wynik to oczywiście:
['aaa111', 'zzz222'] ['111aaa', '222zzz']
I są to po prostu dwie funkcje które przesuwają wszystkie liczby w prawo albo w lewo, przyjmując listę słów do przetworzenia.
Duplikację widać gołym okiem. IDE reaguje na to tak:

PyCharm, bo o nim mowa, podkreśla słowo „processed” i to w obu funkcjach. Po najechaniu na wyróżnione słowo, IDE informuje nas, co mu się nie podoba:
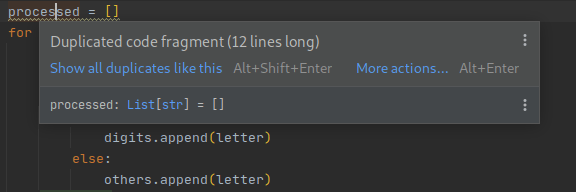
Po kliknięciu „Show all duplicates like this” otwiera się okno:
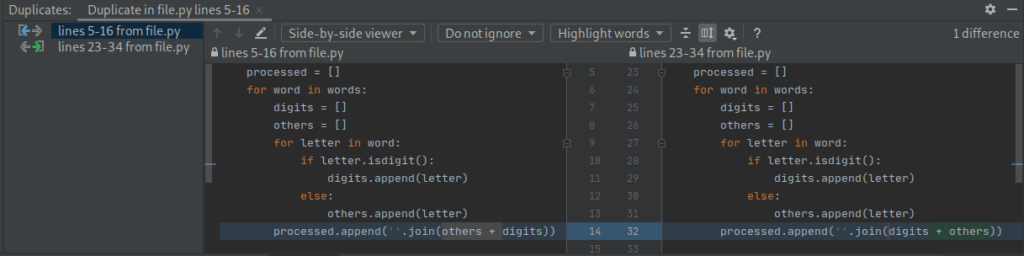
które po lewej stronie pokazuje linie która zostały uznane za duplikat a po prawej stronie diff obu fragmentów, pokazujący różnice.
Więc odpowiadając na pytanie z nagłówka – tak, PyCharm informuje nas jeśli znajdzie duplikaty. Oczywiście nie podejmie on za nas decyzji, jakiego typu duplikat to jest, ale wskaże problematyczne miejsca.
Zmierzając do brzegu
Oczywiście ten problem nie jest niczym nowym i pojawia się w różnych opracowaniach, gdzie jest raz lepiej, raz gorzej, opisany. Kończąc, chciałbym powiedzieć, że powinniśmy zachowajmy umiar w uwspólnianiu kodu jak i technice copy-pasta. Każda sytuacja jest indywidualna i powinna być przemyślana oddzielnie, zgodnie z założeniami projektowymi. Wiele pomóc może nam rozmowa z biznesem.
Mateusz Mazurek



Hej Mateusz ✋,
Ja jestem zwolennikiem pisania wszystkiego od nowa. Lubię także zasadę DRY która trochę kłóci się z założeniem pierwszego zdania.
Jednak jak mogę coś od nowa napisać to chętnie to robię ponieważ ucze się w ten sposób a jestem na etapie nauki oraz przebranżawiania więc mi to pomaga ?.
Ciekaw jestem co to za projekt którego jesteś patronem. Czy polecił byś jakiś fajny kurs do wzorców projektowych w Python? Wiem że wzorce projektowe to uniwersalne zagadnienie ale wolał bym się ich uczyć na przykładach w tym języku ?.
Na Udemy.com znalazłem kursy ale w języku Java. Może byś zaczął o tym pisać na swoim blogu. Chętnie bym poczytał ?.
Pozdrawiam.
Cześć!
Jeśli Twój skill angielskiego Ci pozwala to polecam książkę Sebastiana: https://leanpub.com/implementing-the-clean-architecture – chociaż może być ona trochę za ciężka, skoro jesteś na początku drogi. Wzorce projektowe u mnie na bank się pojawią, ale jeszcze… Nie wiem kiedy:)
Cześć.
Angielski umiem całkiem dobrze. Chętnie tą książkę przeczytam, skoro listingi są w Pythonie.
Brakuje mi jeszcze wiedzy z MVC oraz wzorców projektowych oraz innych rzeczy ale te bym się chętnie nauczył.
Pozdrawiam.
Z polskojęzycznymi terminami mam pewien problem, bo od dawna czytam głównie po angielsku, ale czy tu nie chodzi po prostu o zasadę SRP (Single Responsibility Principle) – czy raczej o złamanie tej zasady?
Cześć, dzięki za komentarz! Hmm, duplikacja może oznaczać złamanie tej zasady ale nie musi.. Chyba ciężko jednoznacznie określić to bez konkretnego kodu, ale w ogólności tak – tematy są ze sobą związane:)
Cześć!
Nie mogę znaleźć jakiś fajnych opracowań (oprócz tego) w internecie na ten temat. Szukałem pod frazami: apparent code duplication, ilussionary code duplication (https://medium.com/decoupled/the-tempting-trap-of-illusory-duplication-f3bf8d816cd6) itp.
Czy możesz podrzucić opracowania, na które się natknąłeś z tym problemem?
Cześć, chyba ten problem nie ma jednej konkretnej nazwy :( a przynajmniej ja nie dokopałem się do miejsca, gdzie by tak było. To trochę kłopotliwe, bo więcej opracowań rzuciłoby światło może pod innym kątem, pokazało temat z innej perspektywy :( tak czy siak, nie umiem pomóc :(