

O monitorowaniu aplikacji
Wstęp
Jak szybko jesteś w stanie znaleźć fragment kodu, który powoduje błąd w Twojej aplikacji? Czy wiesz ile trwają poszczególne procesy? Czy kiedykolwiek zadawałeś sobie te pytania, czy może jesteś jedną z tych osób, które w błogiej nieświadomości czekają na operację na żywym organizmie? Niewystarczający monitoring lub jego brak może doprowadzić do sytuacji, w której, w przypadku wystąpienia awarii, nie będziesz w stanie sprawnie przywrócić działania aplikacji. Przełoży się to na wizerunek firmy, jej obroty a nawet na atmosferę w zespole.
Jeżeli chcesz się dowiedzieć jak uniknąć tego scenariusza, a ponadto jakie korzyści przynosi przemyślany system monitoringu, zapraszam do lektury. Dziś skupimy się na prześledzeniu sterowania w naszej aplikacji. Temat monitoringu zasobów poruszę w innym artykule.
Logi, wszędzie logi…
Pierwsze co przyjdzie nam do głowy w ramach rozwiązywania problemów czy weryfikacji procesu biznesowego to oczywiście odpowiednio rozbudowane logi. Standardowo taki log składa się z Id klienta/procesu, daty i godziny wystąpienia oraz opisu. Aby ułatwić sobie przeszukiwanie logów w takiej postaci możemy dodać spany (zakresy). Każdy span składa się z opisu konkretnej czynności i Id-ka, np DB-SELECT-1234. Dzięki temu możliwe jest szybkie namierzenie konkretnych operacji, czy to biznesowych czy infrastrukturalnych.
Spany możemy zagnieżdżać, tak aby dokładnie umiejscowić konkretne operacje w aplikacji. Sytuacja robi się trochę bardziej skomplikowana, gdy mamy operacje asynchroniczne, wykonywane przez klika skryptów lub architekturę mikroserwisową. Pierwszym problemem jaki się tu pojawi jest kilka miejsc w których zapisujemy nasze logi. W przypadku trzymania logów w plikach tekstowych na serwerach, jedyne co nam pozostaje przy ich analizie to jednoczesne otwieranie wielu dokumentów. Rozwiązać ten problem możemy przenosząc logi w jedno miejsce do agregatora typu elasticsearch. Dodatkowo będziemy musieli wprowadzić kolejny span, dla ułatwienia możemy go nazwać correlation (korelacja), który powiąże operacje wykonywane przez skrypty/serwisy w ramach jednego procesu biznesowego. Tak przygotowane logi dają nam już spore możliwości analizy. Możemy określić czy wszystkie operacje się wykonały i ile trwały. Niestety ich przeszukiwanie może być bardzo utrudnione i męczące. Znacznie łatwiej będzie nam wszystko monitorować z wykorzystaniem odpowiedniego narzędzia.
Przygotowanie aplikacji
Zanim przejdziemy do wyboru odpowiednich narzędzi, zatrzymajmy się jeszcze na chwile przy naszej aplikacji. Nawet najlepszy system do monitoringu nic nam nie da w sytuacji, gdy nasza aplikacja wygląda jak wzorcowy przykład spaghetti code. Bez uporządkowania kodu w logiczną całość, nie ma mowy o dodawaniu monitoringu. Dlaczego?
Po pierwsze, będzie trzeba znaleźć wszystkie miejsca, które wykonują daną czynność np. połączenie do bazy danych. Za każdym razem gdy będziemy dodawać nową funkcjonalność, będziemy musieli pamiętać o uwzględnieniu kodu odpowiedzialnego za monitoring. Jeżeli zapomnimy i nikt nie zwróci na to uwagi podczas CR, nasz monitoring będzie przekłamywał rzeczywistość i pokazywał mniej niż dzieje się faktycznie. W praktyce może to doprowadzić do zarzucenia całego przedsięwzięcia, nikt nie chce korzystać z narzędzia, któremu nie można ufać. Takie podejście zwiększa czas potrzebny na wytworzenie funkcjonalności i wprowadza dodatkową duplikację kodu. Dlatego musimy tak przygotować naszą aplikację, aby czynność, którą chcemy monitorować, była wykonywana tylko w jednym miejscu. Tutaj z pomocą przychodzi nam odpowiednia architektura aplikacji.
Wyjaśnijmy to na przykładzie wspomnianego wcześniej połączenia do bazy danych. Jeżeli korzystamy bezpośrednio z wbudowanego w język programowania mechanizmu do komunikacji z bazą danych, to w każdym miejscu, w którym mamy operacje bazodanowe musimy dodać też kod odpowiedzialny za monitoring. Jeśli posłużymy się odpowiednią abstrakcją i natywny mechanizm przykryjemy naszą klasą, będziemy mogli dodać odpowiedni kod tylko w jednym miejscu. Ktoś kiedyś powiedział, że prawdopodobnie większość problemów architektonicznych można rozwiązać, dodając nową warstwę. Nie wiem czy rozwiąże większość, ale na pewno tutaj pomoże.
Biblioteki, narzędzia i ich zastosowanie
Przejdźmy teraz do wyboru odpowiedniego narzędzia. Jedne z najpopularniejszych to:
- Zipkin
- Jaeger
Aplikacje te składają się z Collectora, który gromadzi dane z wszystkich monitorowanych miejsc, oraz klienta wbudowanego w naszą aplikację. Niektóre narzędzia umożliwiają postawienie lokalnego agenta i prace zarówno w trybie push, gdzie wysyłamy dane do collectora, jak i pull, gdzie w określonych interwałach to collector pobiera dane z Agentów. Sam mechanizm działa na podobnej zasadzie jak opisany wyżej przykład z logami.
Wszystkie te narzędzia mają graficzną prezentację danych, co daje nam dużo większe możliwości niż opisane wcześniej proste logi. Po pierwsze, możemy monitorować wydajność i poszukiwać miejsc, które generują opóźnienia, na przykład namierzyć długo trwające zapytania do DB czy żądania do zewnętrznych serwisów. Kolejną możliwością jest śledzenie zależności i ścieżki sterowania naszej aplikacji. Możemy łatwo określić np. kiedy i ile razy nasza aplikacja odpytuje bazę danych, a w konsekwencji wyśledzić kandydatów nadających się do cache’owania. Mamy także czytelną informację o tym, czy wszystkie elementy procesu biznesowego wykonały się w odpowiedniej kolejności. Idealnie sprawdzają się także przy monitorowaniu aplikacji w architekturze mikorserwisowej (distributed tracing) – po prostu możemy szybko ustalić który z naszych serwisów działa nieprawidłowo.
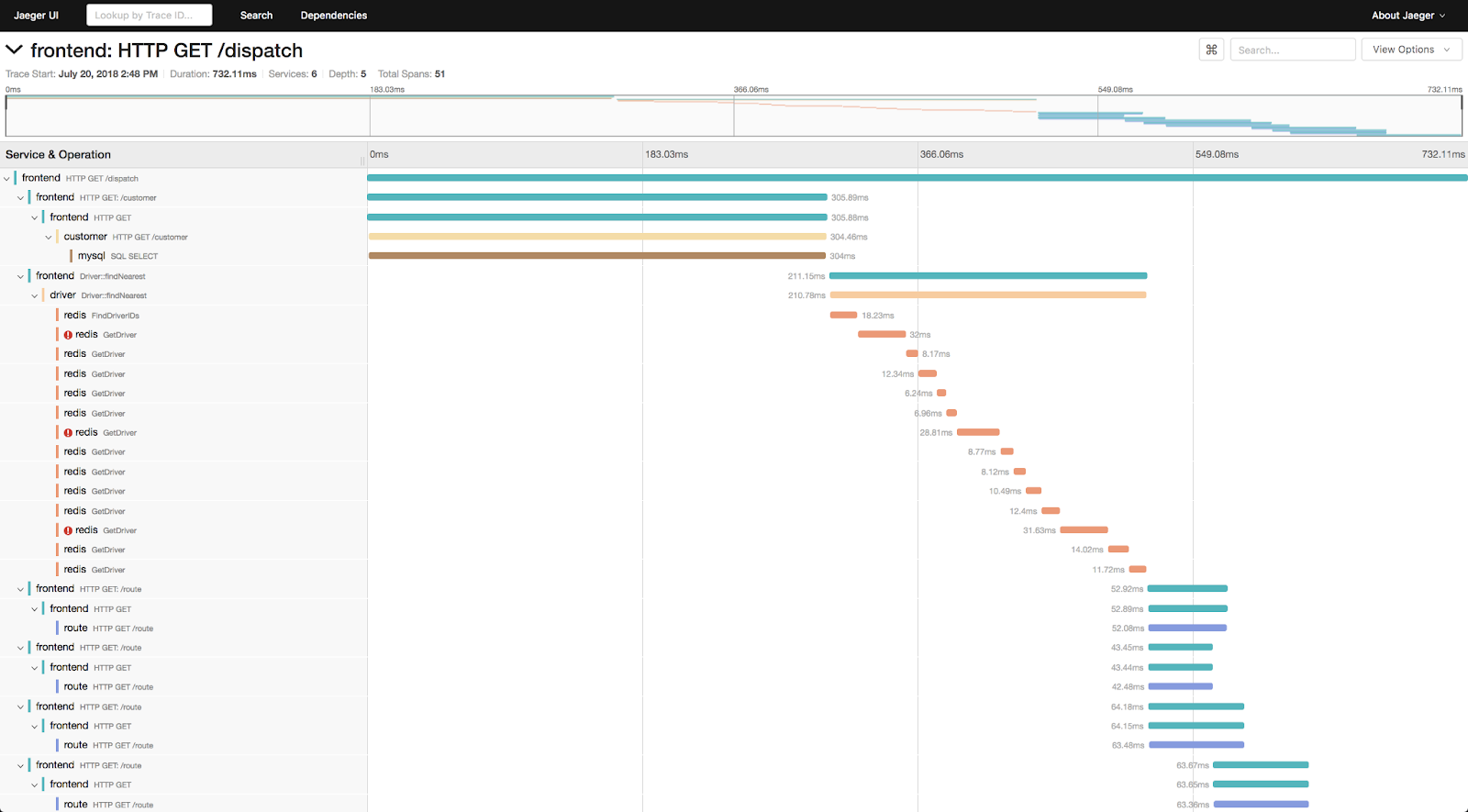
Przykładowy podgląd Jaeger (https://www.jaegertracing.io/)
Proof of concept
Zacznijcie spokojnie. Określcie priorytety, nie wszystkie mechanizmy w Waszej aplikacji muszą mieć monitoring, lub nie wszystkie muszą go mieć od samego początku. Następnie przygotujcie prostego POC’a. Może być to monitoring jednego z zapytań do bazy danych, długiej operacji biznesowej lub komunikacji z zewnętrznym API. Pozwoli to zespołowi i firmie zdobyć potrzebne doświadczenie i odpowiednio skorygować plan na szerokie wprowadzenie monitoringu.
Podsumowanie
W tym artykule dowiedzieliście się czym są i jak działają systemy do monitoringu aplikacji.
A to dopiero ułamek ich możliwości. W kolejnym artykule, już na konkretnym przykładzie zobaczymy jak monitoring działa w praktyce.
Autorem wpisu jest Łukasz Krawczyk PHP Developer w Wakacje.pl, programista z kilkuletnim doświadczeniem, specjalizujący się w integracji i optymalizacji systemów informatycznych. A nade wszystko – czujny obserwator procesu dostarczania oprogramowania.
Mateusz Mazurek



Monitorowanie aplikacji to naprawdę ciekawa praca. Powinniśmy wiedzieć, jak to zrobić.