

Garbage Collector w Pythonie
Cześć.
Notatki do tego artykułu przeleżały w „szufladzie” naprawdę sporo czasu. Nie ma w tym nic złego, realizowałem inne pomysły, ale zawsze miałem ten z tyłu głowy. I jest! Doczekał się realizacji. Zapraszam na artykuł o garbage collectorze.
Pamięć
Każda zmienna którą tworzymy w naszych programach zajmuje jakąś ilość pamięci operacyjnej komputera. W trakcie wykonywania programu często zdarza się, że części zmiennych już nie potrzebujemy i pamięć, którą zajmują należy zwolnić. To bardzo ważna kwestia, bo niezwalnianie pamięci prowadzi do tego, że nasz program potrzebuje jej coraz więcej i więcej, aż może się okazać, że w pewnym momencie, nie będziemy mieli mu już co przydzielić.

Zarządzanie pamięcią w Pythonie
W językach niższego poziomu np. w języku C każda pamięć która została przez nas zaalokowana musi zostać również przez nas zwolniona. Brzmi to dość prosto, ale jeśli program jest bardziej skomplikowany, to takie ręczne zarządzanie pamięcią może przysporzyć kilku siwych włosów. Nie programowałem na tyle długo w C/C++ by znać to z autopsji, ale słyszałem naprawdę zatrważające historie. Z drugiej strony, pewnie nie ma co demonizować, wszystkiego można się nauczyć, jeśli tylko ma się dostatecznie dużo czasu. Tak czy siak, języki szybko zaczęły iść w automatyczne zarządzanie pamięcią. Do tej grupy należy również Python.
Głównym algorytmem stojącym za terminem „zarządzanie pamięcią w Pythonie” jest zliczanie referencji. To dość prosty algorytm, ale wbrew pozorom radzi on sobie nieźle z większością sytuacji. Polega on na ciągłym zliczaniu ilości referencji do każdego z stworzonych obiektów. I jeśli ilość referencji spadnie do zera to obiekt jest usuwany z pamięci. Natychmiast.
Istnieje pewien problem który nie jest rozwiązywalny przez zliczanie referencji.
1 2 | a = [] a.append(a) |
W tym przypadku obiekt listy wskazuje na samą siebie, co tworzy cykl. I tu właśnie tu zliczanie referencji zawodzi. Problem ten w Pythonie rozwiązuje komponent o nazwie garbage collector. Posiada on dodatkowe algorytmy wykrywające cykle i jeśli takowe wykryje – to je przerywa. To natomiast powoduje spadek liczby referencji a w konsekwencji sprzątnięcie obiektu.
Problem z tym podejściem jest taki, że prześledzenie cykli dla wszystkich obiektów które mogą je tworzyć jest dość wolne, więc trzeba było to jakoś zoptymalizować. Rozwiązanie problemu opiera się o hipotezę, która mówi że większość obiektów w naszych programach żyje albo bardzo krótko albo bardzo długo. I jakby się zastanowić, to ma to sens. Obiekty żyjące długo to jakieś sockety, singletony czy loggery a obiekty żyjące krótko to np. zmienne lokalne dla konkretnych funkcji. Tak czy siak, w oparciu o to spostrzeżenie, twórcy Pythona zaimplementowali tzw. generacje. Dla uproszczenia można patrzeć na generacje jak na trzy listy. Każdy nowo stworzony obiekt jest dodawany do listy (generacji) 0. Jeśli obiekt przeżył garbage collection przeprowadzony na liście 0, to jest przesuwany do listy 1, jeśli przeżył ten sam proces ale dla listy 1, to jest przenoszony do listy drugiej. Taki algorytm sprawia, że lista 0 jest dość mała strukturą dla której jest wysokie prawdopodobieństwo że znajdziemy w niej obiekty żyjące krótko. Wniosek z tego jest taki, że przeprowadzanie garbage collection na liście 0 jest tanie, więc możemy je robić często. Natomiast ten sam proces dla listy 2 jest znacznie bardziej skomplikowany – więc przeprowadzamy go rzadziej. W praktyce można taki przypadek sobie spreparować:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | import gc class Test: pass test = Test() print(test) # <__main__.Test object at 0x7fa75fe19110> print(gc.get_objects(generation=0)) # [... <__main__.Test object at 0x7fa75fe19110> ....] gc.collect(generation=0) # manualne odpalenie garbage collector print(gc.get_objects(generation=0)) # brak naszego obiektu print(gc.get_objects(generation=1)) # [... <__main__.Test object at 0x7fa75fe19110> ....] |
Możemy tez podejrzeć ilość referencji do konkretnego obiektu:
1 2 3 4 5 6 7 8 9 10 11 12 | import sys class Test: pass test = Test() print(sys.getrefcount(test)) # 2 # jedna referencja to zmienna test # druga to referencja przekazana do funkcji |
Nie każda referencja się liczy
Python daje możliwość tworzenia tzw słabych referencji, czyli takich które nie podbijają licznika odwołań. To może okazać się bardzo przydatne np. tworząc cache czy jakieś bufory. Podstawowe API jest bardzo proste:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import sys import weakref class Test: pass test = Test() print(test) # <__main__.Test object at 0x7f5f64841670> print(sys.getrefcount(test)) # 2 weakref_test = weakref.ref(test) print(sys.getrefcount(test)) # 2 print(weakref_test) # <weakref at 0x7f5f6483dae0; to 'Test' at 0x7f5f64841670> del test # usuwamy ostatnią silną referencję do obiektu, co się stanie ze słabą referencją? print(weakref_test) # <weakref at 0x7f5f6483dae0; dead> |
Możemy też sprawdzić ile i jakie słabe referencje odnoszą się do naszego obiektu:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import weakref class Test: pass test = Test() print(test) # <__main__.Test object at 0x7f3017a460d0> weakref_test = weakref.ref(test) print(weakref.getweakrefs(test)) # [<weakref at 0x7f3017873a40; to 'Test' at 0x7f3017a460d0>] print(weakref.getweakrefcount(test)) # 1 |
Specjalne typy danych
Moduł weakref dostarcza nam dwa słowniki, które pozwalają na przechowywanie słabych referencji. Jeden pozwala na używanie słabych referencji jako kluczy a drugi jako wartości. A co jeśli jakaś słaba referencja nie będzie już na nic wskazywać? Proste – słownik sam zadba o to by przechowywał tylko istniejące dane. Niżej przykład dla kluczy:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | import weakref class Test: pass test = Test() weakref_dict = weakref.WeakKeyDictionary({ test: "jestem wartoscią" }) print(weakref_dict.data) """ {<weakref at 0x7f878723bb80; to 'Test' at 0x7f87874050d0>: 'jestem wartoscią'} """ del test # usuwamy ostatnią silną referencję print(weakref_dict.data) """ {} """ |
i analogiczny dla wartości:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | import weakref class Test: pass test = Test() weakref_dict = weakref.WeakValueDictionary({ "jestem kluczem": test }) print(weakref_dict.data) """ {'jestem kluczem': <weakref at 0x7f9f4d020b80; to 'Test' at 0x7f9f4d1ea0d0>} """ del test # usuwamy ostatnią silną referencję print(weakref_dict.data) """ {} """ |
Poza słownikami możemy użyć również zbioru:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | import weakref class Test: pass test = Test() weakref_set = weakref.WeakSet({test, Test()}) print(weakref_set.data) """ {<weakref at 0x7f972ec31b80; to 'Test' at 0x7f972edfb0d0>} Tylko jeden element, bo drugi od razu został sprzątnięty. """ del test print(weakref_set.data) """ set() czyli pusto. """ |
Czekaj, stop!
Podoba Ci się to co tworzę? Jeśli tak to zapraszam Cię do zapisania się na newsletter:Jeśli to Cię interesuje to zapraszam również na swoje social media.
Jak i do ewentualnego postawienia mi kawy :)

Czy to jakaś magia?
No właśnie to żadna magia. Te struktury danych wykorzystują pod spodem fakt, że metoda ref, tworząca słabą referencję może przyjąć drugi argument, będący funkcją, która zostanie wykonana, jeśli docelowy obiekt przestanie istnieć. Z taką wiedzą już bardzo łatwo zaimplementować własny, prosty odpowiednik:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | import weakref class OwnWeakSet: def __init__(self, *args): self._inner_set = set() for arg in args: self.add(arg) @property def data(self): return self._inner_set def _remove(self, obj): self._inner_set.remove(obj) def add(self, obj): obj_weakref = weakref.ref(obj, self._remove) # tu użyty drugi argument self._inner_set.add(obj_weakref) class Test: pass test = Test() my_weak_set = OwnWeakSet() my_weak_set.add(test) print(my_weak_set.data) """ {<weakref at 0x7f53f8356c20; to 'Test' at 0x7f53f84472e0>} """ del test print(my_weak_set.data) # set() |
Wizualizacja działania GC
Relatywnie prosto jest zmusić Pythona by pokazał nam działanie swojego GC. A łącząc to z biblioteką która potrafi zbierać próbki zużywanej pamięci i zrobić z nich wykres dostajemy fajnie zwizualizowany proces. Uruchamiamy taki kod:
1 2 3 4 5 6 7 8 9 10 11 12 | from time import sleep class A: def __init__(self): self.vars = list(range(1000000)) for _ in range(1000): a = A() a.self_ref = a sleep(0.00001) |
ale nie standardowo z PyCharma a z terminala, używając biblioteki mprof:
mprof run python challenge.py
Gdy jej działanie się zakończy wykonujemy polecenie:
mprof plot
które uruchamia nam wykres:
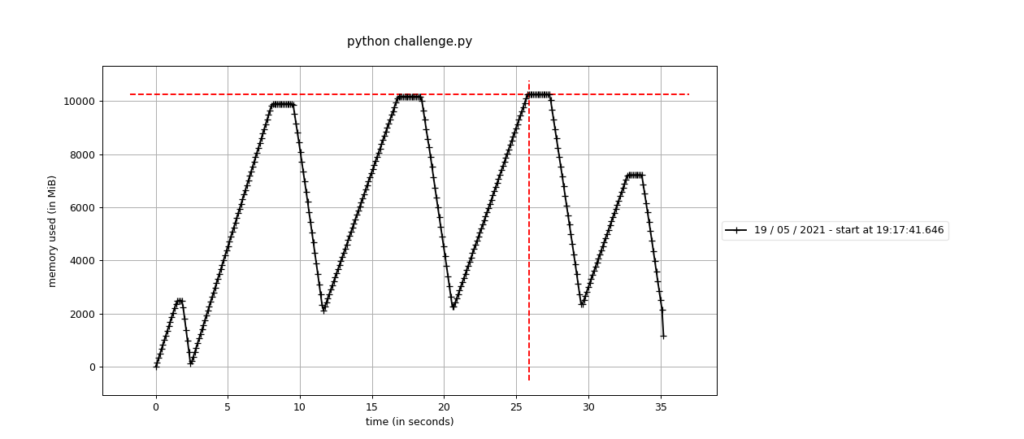
pokazujący zużycie pamięci w czasie.
Pierwszy wzrost i zaraz spadek jest prosty do wyjaśnienia. Uruchamiając interpreter Pythona, ładuje on sporo obiektów do pamięci, więc nasza pętla szybko przekroczyła próg uruchomienia GC. Kolejne trzy to właściwa wizualizacja działania GC. Ostatnia sytuacja, mimo że na pierwszy rzut okna nie wygląda zbyt intuicyjnie, to po prostu efekt tego, że pętla się skończyła, nim przekroczyła próg GC. Zaraz za pętlą program praktycznie się kończy, więc zwalania jest pamięć.
Z wykresu wynikają jeszcze dwa wnioski:
- są momenty kiedy zużycie pamięci jest stałe – jest to czas trwania GC, ponieważ jego uruchomienie zawiesza program, a więc nasza pętla nie alokuje wtedy obiektów. Zwróć uwagę, że to nie są krótkie odcinki czasu,
- czas potrzebny na faktycznie zwolnienie zasobów też nie jest mały
Progi uruchamiające GC
Python daje nam pewne możliwości ingerencji w to, jak i kiedy zadziała GC. Prawie na pewno nie musisz tego zmieniać. Mimo wszystko, wiedzieć warto. Aktualne wartości progów można podejrzeć funkcją gc.get_threshold():
1 2 3 4 | import gc print(gc.get_threshold()) # 700, 10, 10 |
Wartości te mówią, że GC dla generacji zero uruchomi się jeśli różnica między alokacjami obiektów a ich dealokacjami będzie większa niż 700. Mówiąc prościej – uruchomi się, jeśli 700 obiektów nie zwolni się na drodze zliczania referencji (podejrzenie cyklicznej referencji). Kolejne dwie liczby to mnożniki. Oznacza to, ze GC dla generacji pierwszej uruchomi się, jeśli 10 razy uruchomi się GC dla generacji zero. I analogicznie, GC dla generacji drugiej uruchomi się jeśli GC dla generacji pierwszej uruchomi się 10 razy.
Zmieńmy te progi na 100, 10, 10, co sprawi, że GC uruchomi się 7 razy częściej. Kod dużo się nie zmieni:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | from time import sleep import gc class A: def __init__(self): self.vars = list(range(1000000)) gc.set_threshold(100, 10, 10) for _ in range(1000): a = A() a.self_ref = a sleep(0.00001) |
Natomiast wykres już znacznie bardziej:
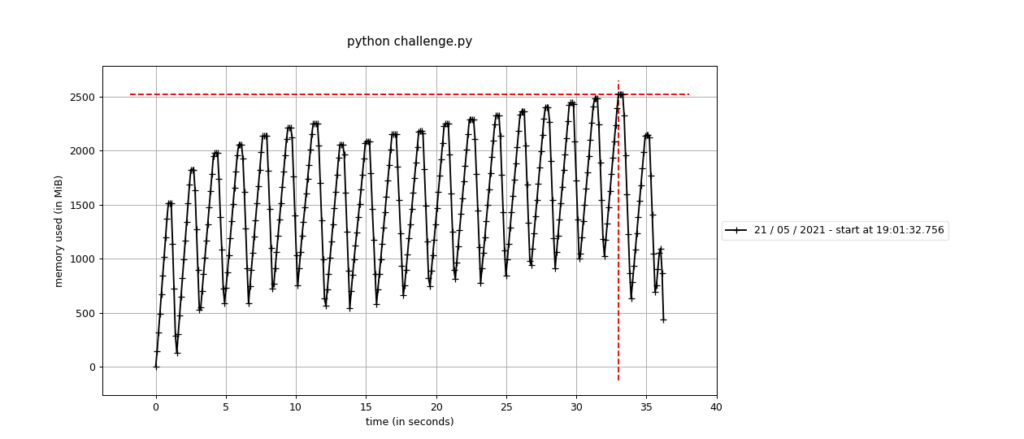
To co łatwo zauważyć, to to, że częstotliwość uruchamiania się GC jest mniej więcej 7 większa niż w przykładzie, gdzie nie modyfikowaliśmy progów. Ponad to, porównując dalej, łatwo dostrzec, że program sumarycznie zużył znacznie mniej pamięci. Ale też czas wykonywania się jest większy o około 2-3 sekundy. Jednym słowem: coś za coś.
Ciekawostka: GC na PyPy
Implementacja Pythona o której piszę w tym artykule to oczywiście CPython (3.9.x). Część ludzi wie, że istnieje kilka alternatywnych implementacji. Czysta inżynierska ciekawość sprawiała, że uruchomiłem nasz kawałek kodu (bez modyfikacji progów) właśnie na PyPy (7.1.1, Python 3.6.x), czyli implementacji Pythona w Pythonie. Rezultat jest ciekawy:
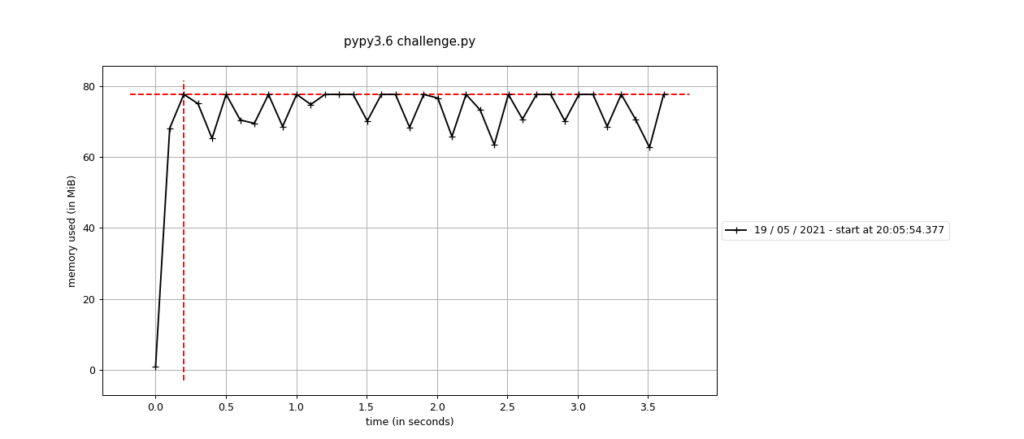
Zwróć uwagę na:
- czas wykonywania się programu,
- zużycie pamięci,
- zupełnie inne zachowanie się GC.
Dwa pierwsze punkty pozostawię bez komentarza, bo to że PyPy jest szybszy od CPythona jest jasne i nawet sam twórca Pythona swojego czasu polecał PyPy:
"If you want your code to run faster, you should probably just use PyPy." Guido Van Rossum
Natomiast trzeci punkt to po prostu kwestia innego algorytmu GC użytego w PyPy.
Ciekawostka 2: GC na Jython
I znów ciekawość zwyciężyła. Tym razem chciałem zobaczyć jak implementacja Pythona w Javie sobie radzi z naszym programem. Wynik wygląda tak:
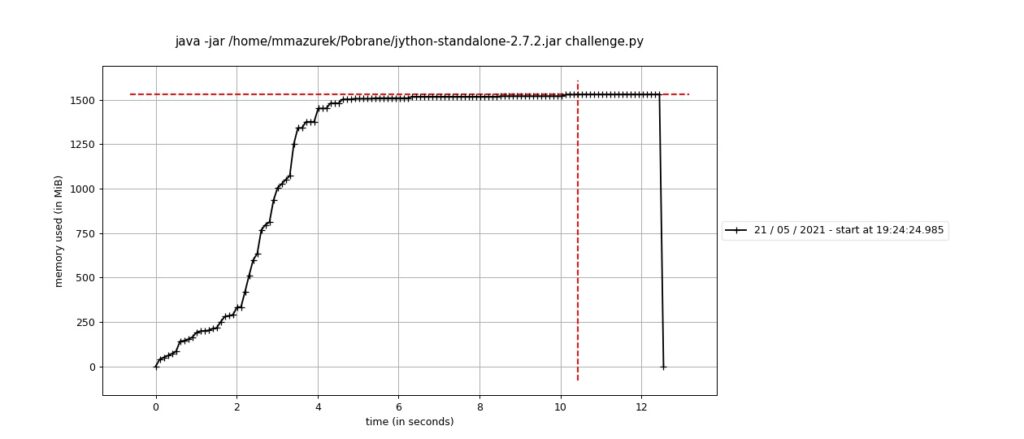
Niestety nie wiem zbyt wiele o ekosystemie JVMa, więc będę się silił na interpretację tego wykresu. Ale może Ty wiesz więcej? Jeśli tak, to zostaw komentarz.
Zmierzając do brzegu
GC i jego działanie w Pythonie to mega ciekawe zagadnienia. Wiedza o tym jak to działa może przydać się w najmniej oczekiwanym momencie i uratować nie jeden projekt. Mam nadzieję, że czytało się ciekawie.
Mateusz Mazurek



Świetny artykuł.
Może jestem masochistą, ale brakowało mi tego w Pythonie :D
Dzięki! :D ale, że brakowało świetnych artykułów? :D
Brakowało GC w Pythonie oczywiście, by nie było wątpliwości :P
Fajny artykuł.
Chciałem się zapytać czy garbage colector wpływa na wydajność działania programu, a jeśli tak to jak?
Oraz gdzie to się używa najbardziej? Obecnie komputery mają standardowo 16 GB pamięci operacyjnej. Czy jest to bardzo dużo czy za mało?
Kiedy standardowy komputer ma tyle pamięci to przy jakich sytuacjach GC musi ciężko pracować?
Sorry za pytania newbiego, jednak trzeba coś się dokształcić ?.
Generalnie Garbage Collector jest częścią technologii z której korzystasz, tj Java, JavaScript, C# czy Python posiadają garbage collector, który odpowiada za cały lub część memory managementu, i nie ma tu dyskusji „gdzie się używa najbardziej”, bo to po prostu tak działa. GC, a więc fragment kodu który co jakiś czas przechodzi przez całą pamięć zajętą przez twój program, ma negatywny wpływ na wydajność, w zależności od scenariusza może mieć większy (dużo tworzonych i niszczonych obiektów) lub mniejszą, ale zawsze jakąś. Punkt drugi to fakt że GC odpowiada tylko za pamięć zaalokowaną przez program więc ilość pamięci w komputerze nic tu do rzeczy nie ma, co najwyżej o tyle że jeśli masz więcej obiektów to garbage collection zajmie więcej czasu i jeśli masz mało pamięci dostępnej to GC musi włączać się częściej. A 16 GB to po prostu obecnie standard, ciężko odpowiedzieć tak ogólnie bo różne GC działają na różnych zasadach.
Dzięki Krzysztof za wyczerpującą odpowiedź.
W gruncie rzeczy odpowiedź Krzysztofa wyczerpuje temat :D
Zdecydowanie jedna z tych rzeczy, której od dawna brakowało w Pythonie. Również uważam, że to zdecydowanie jedna z najlepszych informacji.
Świetny artykuł. Brakuje mi takiego kontentu w polskiej blogosferze!
Dzięki! <3
Świetny i świetnie napisany artykuł, mój pierwszy i zostanę tu na dłużej :)
Pytanie: czy można, powiedzmy z masochistycznych powodów, całkowicie wyłączyć GC i robić to co on, ale ręcznie?
Wyłączyć udałoby się, ale czy zastąpić? Chyba na poziomie Pythona średnio by to działało ale już na poziomie CAPI Pythona, myślę, że można by było coś podziałać:)