
Farma Flasków i HaProxy jako przykład load balancingu
Witam Was świątecznym nastrojem ;) Mimo ganiania za króliczkami, barankami i borówkami przedstawię Wam dziś dwie fajne rzeczy – Flaska i HaProxy.
We wpisie zajmiemy się tematyką load balancingu – czyli równoważenia ruchu – a więc rozwiązania problemu kiedy na naszą stronę dostajemy N requestów i to N jest o K za duże ;) a więc nasz serwer się nie wyrabia z ich obsługą.
Aby sytuację poprawić możemy na 3 „główne” sposoby:
- Wkładamy wszędzie gdzie możemy cache – czyli odciążamy nasz serwer HTTP.
- Skalujemy naszą infrastrukturę horyzontalnie – czyli dokładamy więcej podobnych serwerów.
- Skalujemy wertykalnie – czyli do naszej jednostki dodajemy więcej RAMu, zmieniamy dysk na SSD itp.
My dziś zajmiemy się skalowaniem horyzontalnym. Ma ono swoje plusy:
- Jednostki są odseparowane od siebie – awaria jednej nie powoduje awarii całej naszej usługi
- Jednostki mogą być w różnych miejscach geograficznych – co znaczy że routing może być szybszy dla konkretnej lokalizacji
- Zawsze możemy dodać kolejny serwer – a w porównaniu do wertykalnego podejścia – nie zawsze dodamy więcej RAMu
Ale ma też wady – np. przechowywanie sesji użytkowników czy ewentualne problemy ze spójnością systemu itp – ale generalnie idzie się w tę stronę.
Problem pojawia się gdy chcemy osiągnąć sytuację w której ruch kierowany na naszą stronę jest dystrybuowany na każdy z naszych serwerów równomiernie:
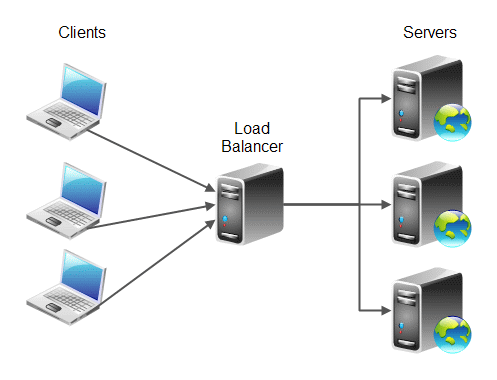
I jak obrazek pokazuje – rozwiązaniem jest Load Balancer. Może on być software’owy lub hardware’owy. My dziś zajmiemy się, rzecz jasna, rozwiązaniem software’owym ;)
Zacznijmy od Flaska.. Flask to biblioteka Pythonowa która pozwala szybko i łatwo postawić serwer HTTP. Jest dość prosta i mała.
Zainstalować możemy ją pipem:
1 | pip install flask |
Flask w domyślnej konfiguracji jest synchroniczny a więc może przyjąć jednego klienta na raz.
Kawałek kodu który uruchomi nam taki serwer to:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #!/usr/bin/python from flask import Flask from time import sleep import sys app = Flask(__name__) @app.route('/') def hello(): sleep(5) return 'Uruchomiono mnie na porcie '+str(sys.argv[1]) if __name__ == '__main__': app.run(host='0.0.0.0',port=int(sys.argv[1])) |
Mapujemy funkcję hello na adres roota. Akcja będzie wykonywać się 5 sekund – sleep nam to zapewnia. Serwer będzie bindować się na wszystkich interfejsach i na porcie przekazanym jako argument.
Oczywiście Flask może przyjąć więcej niż jednego klienta jeśli poprawimy mu nieco konfigurację:
1 | app.run(host='0.0.0.0',port=int(sys.argv[1]), threaded=True) |
Parametr threaded będzie przekazany do werkzeug.serving.run_simple – czyli serwera który jest pod spodem Flaska. A z jego dokumentacji wiemy że parametr ten spowoduje przyjęcie każdego requesta w osobnym wątku:
1 | threaded – should the process handle each request in a separate thread? |
Sprawdziłem to – działa.
Ale na potrzeby tego wpisu nie będziemy korzystać z tej opcji. Możliwość przyjęcia jednego klienta na raz zasymuluje nam sytuację w której mamy bardzo obciążony serwer HTTP.
Poza tym Flask ma też np. bardzo fajny tryb debuggera. Jeśli dodamy do konfiguracji debug:
1 | app.run(host='0.0.0.0',port=sys.argv[1], debug=True) |
To uruchamiając dostaniemy dodatkową informację:
1 2 3 | * Restarting with stat * Debugger is active! * Debugger pin code: 892-250-272 |
I sprawimy że w obsłudze requesta zrobimy jakiś np. błąd który wyrzuci wyjątek to dostaniemy taki oto komunikat:
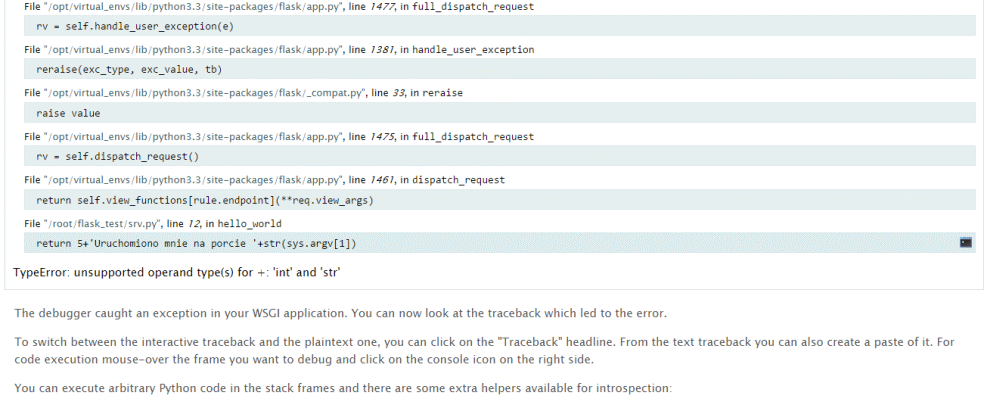
A jak klikniemy na małą ikonkę terminala i podamy PIN który dostajemy przy uruchomieniu to mamy interaktywną konsolkę gdzie możemy podejrzeć np. wartości zmiennych:

Super sprawa ;) ogólnie Flask ma sporo fajnych rzeczy – sesje, autoryzacje, template’ki.
Rzecz jasna biblioteka ta nie nadaje się na produkcję – służy raczej do developmentu.
Pobawiliśmy się Flaskiem a czas wrócić do głównego tematu. A więc mamy serwer HTTP który może przyjąć ograniczoną ilość połączeń. U nas to jest jedno połączenie. Nie zadowala nas to więc chcemy przeskalować naszą infrastrukturę horyzontalnie. A więc tworzymy 6 instancji Flaska :D Wpis dodajemy do supervisora (nie wiesz co to – przeczytaj):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | [program:http_5006] command=python /root/flask_test/srv.py 5006 user=root stdout_logfile=/var/log/http_5006.log stderr_logfile=/var/log/http_5006.log [program:http_5001] command=python /root/flask_test/srv.py 5001 user=root stdout_logfile=/var/log/http_5001.log stderr_logfile=/var/log/http_5001.log [program:http_5002] command=python /root/flask_test/srv.py 5002 user=root stdout_logfile=/var/log/http_5002.log stderr_logfile=/var/log/http_5002.log [program:http_5003] command=python /root/flask_test/srv.py 5003 user=root stdout_logfile=/var/log/http_5003.log stderr_logfile=/var/log/http_5003.log [program:http_5004] command=python /root/flask_test/srv.py 5004 user=root stdout_logfile=/var/log/http_5004.log stderr_logfile=/var/log/http_5004.log [program:http_5005] command=python /root/flask_test/srv.py 5005 user=root stdout_logfile=/var/log/http_5005.log stderr_logfile=/var/log/http_5005.log |
I uruchamiany:
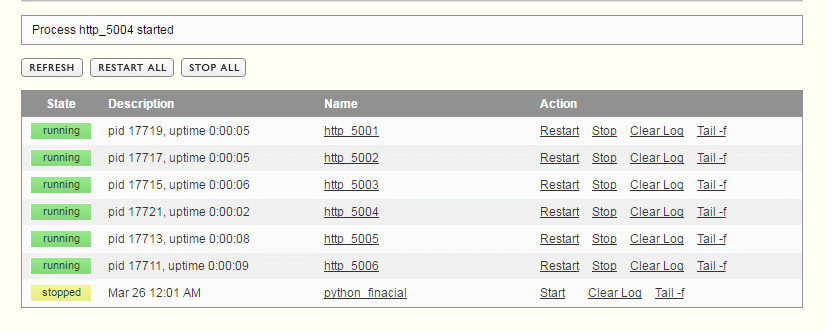
Ostatni proces to proces z poprzedniego wpisu. Nie patrzymy na niego. A więc mamy farmę Flasków :D na portach od 5001 do 5006 ;) Więc jak otworzymy w przeglądarce nasz IP z jednym z tych portów to po 5 sekundach (sleep) otrzymamy odpowiedź.
No i fajnie, mamy 6 takich serwerków, ale to każdy oddzielnie pozwala na przyjęcie jednego połączenia a My chcemy ruch przekierować do każdego z nich tak aby uzyskać możliwosć 6 jednoczesnych połączeń.
I tutaj wchodzi na scenę HaProxy. Jest to software’owy load balancer. Pozwala na rozdystrybuowanie ruchu na N serwerów.
Pracuję na CentOSie 6.5 – więc komendy instalacyjne mogą się nieco różnic, ale Internet bardzo szybko Wam podpowie jakie powinny być Was waszych dystrybucji.
HaProxy instalujemy:
1 | sudo yum install haproxy |
Następnie edytujemy plik /etc/haproxy/haproxy.cfg. W tym pliku będzie cała konfiguracja naszego load balancera. Konfiguracja jest podzielona na kilka sekcji, więc pierw przejdziemy przez każdą sekcję a potem pokażę jak wygląda całość.
Sekcja global
1 2 3 4 5 6 7 | global log /dev/log local0 log 127.0.0.1 local1 notice maxconn 200000 user haproxy group haproxy daemon |
Ustawimy w niej gdzie mają pisać się logi (/var/log/messages), maksymalną ilość połączeń, usera, grupę. Natomiast daemon uruchamia haproxy jako demona:
Makes the process fork into background. This is the recommended mode of
operation. It is equivalent to the command line „-D” argument. It can be
disabled by the command line „-db” argument.
Dalej mamy sekcję defaults:
1 2 3 4 5 6 7 8 9 10 11 | defaults log global mode http option httplog option dontlognull retries 3 option redispatch maxconn 200000 timeout client 25s timeout connect 5s timeout server 180s |
Ustawiamy zdefiniowanego loga, tryb pracy na http, informacja na ten temat wyciągnięta z dokumentacji:
Right now, two major proxy modes are supported : „tcp”, also known as layer 4,
and „http”, also known as layer 7. In layer 4 mode, HAProxy simply forwards
bidirectional traffic between two sides. In layer 7 mode, HAProxy analyzes the
protocol, and can interact with it by allowing, blocking, switching, adding,
modifying, or removing arbitrary contents in requests or responses, based on
arbitrary criteria.
Oraz opcje httplog i dontlognull:
Enable logging of HTTP request, session state and timers
Enable or disable logging of null connections
retries to oczywiście ilość prób pogadania z serwerami zanim uzna się połączenie za nieudane. Przydatna opcja to redispatch:
In HTTP mode, if a server designated by a cookie is down, clients may
definitely stick to it because they cannot flush the cookie, so they will not
be able to access the service anymore.Specifying „option redispatch” will allow the proxy to break their
persistence and redistribute them to a working server.It also allows to retry last connection to another server in case of multiple
connection failures. Of course, it requires having „retries” set to a nonzero
value.This form is the preferred form, which replaces both the „redispatch” and
„redisp” keywords.If this option has been enabled in a „defaults” section, it can be disabled
in a specific instance by prepending the „no” keyword before it.
No i timeout’y:
timeout client – Set the maximum inactivity time on the client side.
timeout server – Set the maximum inactivity time on the server side.
timeout connect – Set the maximum time to wait for a connection attempt to a server to succeed.
To była typowa konfiguracja HaProxy. Teraz czas na nasz właściwy load balancer:
Sekcja frontend :
1 2 3 4 | frontend front bind *:80 mode http default_backend back |
Tworzymy frontend o nazwie front który stoi na porcie 80 i jego domyślnym backendem jest backend o nazwie back.
Teraz dodamy backend:
1 2 3 4 5 6 7 8 9 10 11 | backend back mode http balance roundrobin option httpclose option forwardfor server webserver01 127.0.0.1:5001 check server webserver02 127.0.0.1:5002 check server webserver03 127.0.0.1:5003 check server webserver04 127.0.0.1:5004 check server webserver05 127.0.0.1:5005 check server webserver06 127.0.0.1:5006 check |
opcja balance określa algorytm który będzie używany do wyboru serwera obsługującego żądanie. Tutaj mamy roundrobin. Inne możliwości jak i opis tej możecie zobaczyć w dokumentacji.
Sporo w tym wpisie odniesień do suchej dokumentacji, ale ciężko bez niej coś przedstawić rzetelnie. A nie widzę sensu przepisywania tego :P nie jest to kreatywne.
Dwie kolejne opcje to:
If „option httpclose” is set, HAProxy will work in HTTP tunnel mode and check
if a „Connection: close” header is already set in each direction, and will
add one if missing.
forwardfor – Enable insertion of the X-Forwarded-For header to requests sent to servers
Kolejne 6 linijek to już zdefiniowane servery backendowe – czyli nasze Flaski. Opcja check pozwala na monitoring ich „stanu zdrowia”.
Ostatnią sekcją jest listen:
1 2 3 4 | listen sts *:1936 mode http stats enable stats uri / |
Uruchamiamy tutaj statystyki HaProxy na porcie 1936 po adresem roota. Bez autoryzacji.
A więc całość wygląda tak:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | global log /dev/log local0 log 127.0.0.1 local1 notice maxconn 200000 user haproxy group haproxy daemon defaults log global mode http option httplog option dontlognull retries 3 option redispatch maxconn 200000 timeout client 25s timeout connect 5s timeout server 180s frontend front bind *:80 mode http default_backend back backend back mode http balance leastconn option httpclose option forwardfor server webserver01 127.0.0.1:5001 check server webserver02 127.0.0.1:5002 check server webserver03 127.0.0.1:5003 check server webserver04 127.0.0.1:5004 check server webserver05 127.0.0.1:5005 check server webserver06 127.0.0.1:5006 check listen sts *:1936 mode http stats enable stats uri / |
Sprawdźmy teraz czy to działa. Użyjemy grequests (pip install grequests) czyli asynchronicznych żądań HTTP – żeby wywołać w tym samym czasie adres pod którym stoi HaProxy. Logi pokażą nam godzinę o której odpowiedź została wysłana.
Kawałek Pythona:
1 2 3 4 | import grequests rs = (grequests.get("http://adres_pod_którym_stoi_HaProxy/") for i in range(6)) grequests.map(rs) |
No i logi HaProxy:
1 2 3 4 5 6 7 8 9 10 11 | Mar 26 15:29:32 mmazurek haproxy[17910]:adres_pod_którym_stoi_HaProxy:40162 [26/Mar/2016:15:29:26.995] front back/webserver01 0/0/0/5009/5009 200 185 - - ---- 6/6/5/0/0 0/0 "GET / HTTP/1.1" Mar 26 15:29:32 mmazurek haproxy[17910]: adres_pod_którym_stoi_HaProxy:40161 [26/Mar/2016:15:29:26.995] front back/webserver02 2/0/0/5008/5010 200 185 - - ---- 6/6/4/0/0 0/0 "GET / HTTP/1.1" Mar 26 15:29:32 mmazurek haproxy[17910]: adres_pod_którym_stoi_HaProxy:40160 [26/Mar/2016:15:29:26.995] front back/webserver03 5/0/0/5007/5012 200 185 - - ---- 6/6/3/0/0 0/0 "GET / HTTP/1.1" Mar 26 15:29:32 mmazurek haproxy[17910]: adres_pod_którym_stoi_HaProxy:40159 [26/Mar/2016:15:29:26.995] front back/webserver04 7/0/0/5009/5016 200 185 - - ---- 6/6/2/0/0 0/0 "GET / HTTP/1.1" Mar 26 15:29:32 mmazurek haproxy[17910]: adres_pod_którym_stoi_HaProxy:40158 [26/Mar/2016:15:29:26.995] front back/webserver05 11/0/0/5006/5017 200 185 - - ---- 6/6/1/0/0 0/0 "GET / HTTP/1.1" Mar 26 15:29:32 mmazurek haproxy[17910]: adres_pod_którym_stoi_HaProxy:40157 [26/Mar/2016:15:29:26.994] front back/webserver06 14/0/0/5007/5021 200 185 - - ---- 6/6/0/0/0 0/0 "GET / HTTP/1.1" |
Z logów można wywnioskować że przetworzono 6 requestów, każdy na innym serwerze (Flasku). Odpowiedź została odesłana z każdego Flaska w tym samym czasie.
A więc udało się nam przeskalować naszą infrastrukturę horyzontalnie. Dodaliśmy 5 serwerów i otrzymaliśmy liniowy wzrost efektywności – jesteśmy w stanie obsłużyć 6 requestów jednocześnie :)
Gdybyś wszedł na stronę gdzie swoi Twój HaProxy to za każdym F5 otrzymywał byś zwrot z innego serwera o czym informował by napis „Uruchomiono mnie na porcie 5001”, „Uruchomiono mnie na porcie 5002” itp.. ;)
Dla potwierdzenia w tym kodzie z grequests podałem adres do jednego flaska i oto logi z Flaska:
1 2 3 4 5 6 | source_ip - - [26/Mar/2016 15:37:06] "GET / HTTP/1.1" 200 - source_ip - - [26/Mar/2016 15:37:11] "GET / HTTP/1.1" 200 - source_ip - - [26/Mar/2016 15:37:16] "GET / HTTP/1.1" 200 - source_ip - - [26/Mar/2016 15:37:21] "GET / HTTP/1.1" 200 - source_ip - - [26/Mar/2016 15:37:26] "GET / HTTP/1.1" 200 - source_ip - - [26/Mar/2016 15:37:31] "GET / HTTP/1.1" 200 - |
Każdy request jest od siebie oddalony w czasie o 5 sekund. Nie ma przetwarzania współbieżnego.
Super sprawa, nie? Poza tym warto zerknąć na staty:
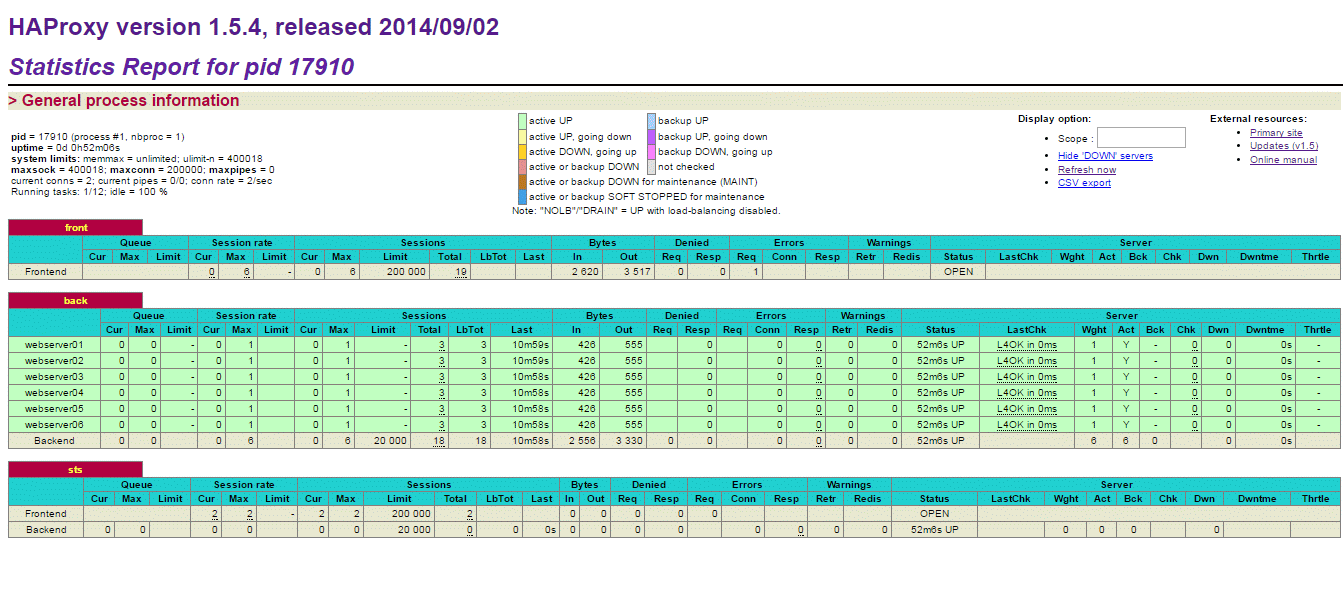
Jeśli np. w supervisorze wyłączymy jeden z serwerów:
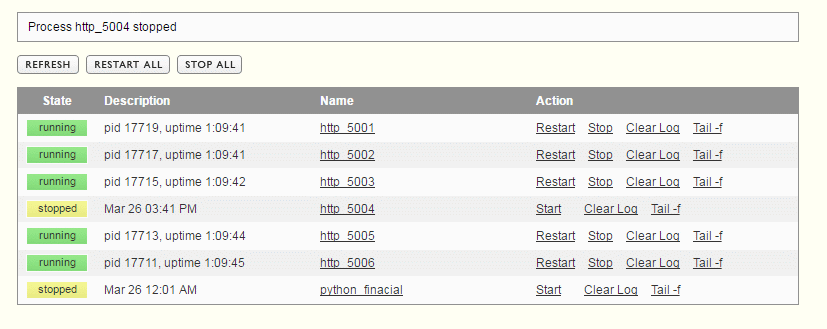
To HaProxy szybko to zauważy i odnotuje w statystykach:
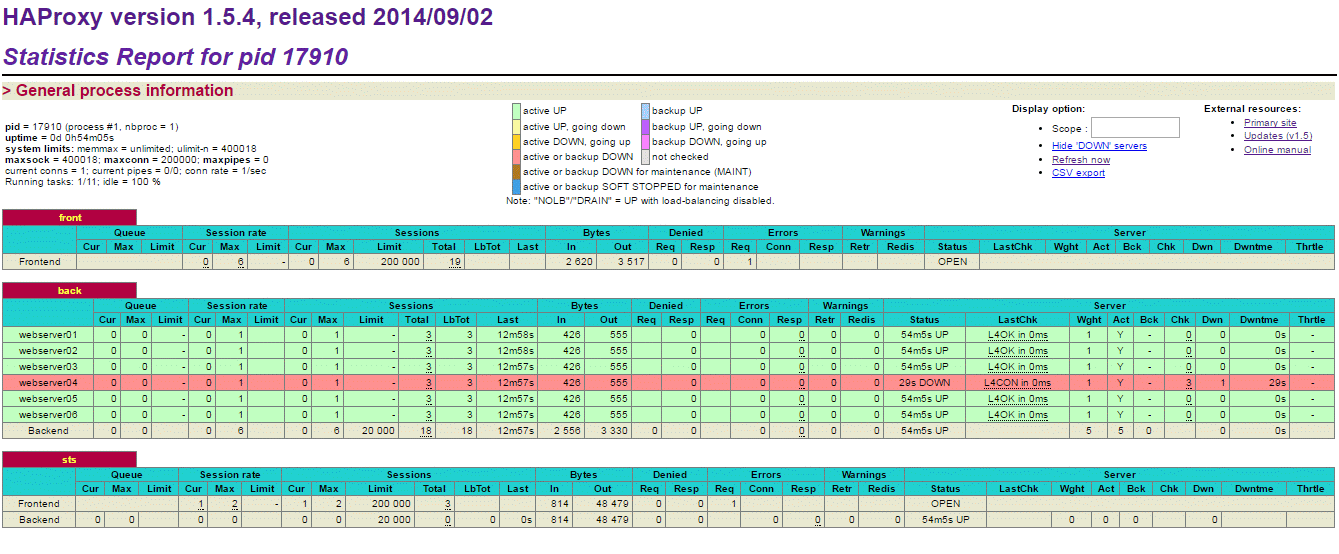
Fajne statystyki, ale czasem też nie chcemy ich wystawiać na zewnątrz albo basic auth jest nie wystarczające. Wtedy możemy skorzystać np. z haproxyctl – takiej tam alternatywy w konsoli. Łudząco przypomina supervisorctl ;) ale w sumie to nie jest minus.
Tak czy siak poznaliśmy dziś sporo nowych rzeczy. A co ważniejsze, nowych i przydatnych.
HaProxy nie musi być tylko load balancerem. Zauważ proszę że w configu serwery podawałem po adresie lokalnym, więc nie musimy ich bindować na wszystkie interfejsy co podnosi poziom bezpieczeństwa.
Poza tym HaProxy wynosi na zewnątrz jeden port – port frontendu. Pozwala to np. na zmniejszenie progu wejścia w swoją aplikację, tzn jeśli nasza aplikacja ma poza HTTP jakieś websockety to czasem wymaga to otwierania portów u klientów co zazwyczaj jest problematyczne. Jeśli wszystko puścimy przez port 80 to nadal możemy mieć swoje N websocketów ale nie musimy nic u klientów otwierać.. :) czysty profit.
A więc tym zakończę wpis.. I wracam do baranków, króliczków i jajeczek.. ;)
Mateusz Mazurek


