
Asynchroniczna kolejka zadań na przykładzie aplikacji konwertującej pliki wideo
Cześć ;) zbudujemy dziś nietrywialną aplikację w architekturze mikro serwisów z użyciem kolejki zadań – Celery. Niestety po tym wpisie będzie chwila przerwy z nowymi postami gdyż czas najwyższy zająć się swoją pracą magisterską którą również tutaj pokrótce przedstawię jak już będzie gotowa ;)
![]()
A wracając….
Napiszmy aplikację która będzie konwertowała pliki wideo do formatu który pozwala na odtwarzanie ich wykorzystując do tego standardowy tag video z HTML5.
Celery – dokładnie to Celery Task Queue – to otwarto źródłowa asynchroniczna kolejka zadań. Jest napisana w Pythonie i jej działanie to w skrócie wykonywanie zdefiniowanych przez nas kawałków kodu w trybie asynchronicznym. A więc piszemy kawałek kodu, zależny od jakiś argumentów (task) i jeśli wywołamy to zadanie, podając te argumenty to Celery wykona nasz kod asynchronicznie.
Celery będzie kolejkować sobie zadania a więc jeśli napłynie więcej zadań niż workerów Celery odpaliło to będą one czekały w kolejce aż inne się zakończą.
Idea jest ogólnie łatwa, prosta i przyjemna. Podobnie z instalacją Celery:
1 | pip install celery |
i już mamy naszą kolejkę zainstalowaną. Aby jej użyć musimy zdefiniować nasze taski.
Iiii tutaj chwilkę się wstrzymam z kodem Pythona, bo pierw należy przemyśleć co chcemy zrobić..
Ano chcemy konwertować pliki wideo do formatu który będzie mógłby być odtwarzana w tym standardowym player’rze video z HTML5. A więc będziemy potrzebować konwertera.
A więc musimy sobie doinstalować do naszego CentOSa jakiś konwerter. Ja wybrałem HandBrake’a w wersji 0.10.2. Oczywiście wystarczy nam HandBrake bez GUI a więc samo HandBrakeCLI.
Aby go zainstalować należy ściągnąć ten release z GITa i skompilować ze źródeł. Trwa dość długo ale jest dość bezproblemowe. Doinstalować będzie trzeba sporo, ale większość znajdziecie w necie. Ja musiałem poza tymi z innych instrukcji doinstalować jeszcze lame (też skompilować ze źródeł) i paczkę x264-devel. O i jeszcze coś zlinkować do innego katalogu musiałem. Ale udało się w 30 minut więc jest nieźle ;)
A więc nasze pliki będziemy konwertować w poniższy sposób – jest to komenda linuxowa:
1 | /usr/local/bin/HandBrakeCLI -i inupt_file -o output_file -e x264 -q 22 -r 15 -B 96 -O |
No i wyjaśnienia co do przełączników:
-i original file
-o convert to destination file
-e x264: video format H264
-q or –quality: controls the video quality.(RF 0 applies no compression. RF 20 throws away detail.
-r or –rate: controls the video framerate, or FPS. Your options are 5, 10, 12, 15, 23.976, 24, 25, or 29.97.
-B or –ab: allows you to set an average audio bitrate in kilobits per second. 64 is good for stereo.
-O or –optimize: Rearranges MP4 files so they play better over the web as progressive downloads.
Pliki będą konwertowane do *.mp4.
Skoro to już ustaliliśmy to czas na kod. Tworzymy sobie nowy moduł Pythona, setup.py:
1 2 3 4 5 6 7 8 | from setuptools import setup setup( name='tasks', version='0.1.5', author='m.mazurek', packages=["converters"] ) |
Celery należy skonfigurować. A więc w __init__.py naszego pakietu converters napiszemy coś takiego:
1 2 3 4 5 6 7 8 9 10 11 | from celery import Celery app = Celery('tasks', broker='redis://localhost/1') app.conf.update( CELERY_ACCEPT_CONTENT=['json'], CELERY_TASK_SERIALIZER='json', CELERYD_CONCURRENCY = 3, CELERY_RESULT_SERIALIZER='json', CELERY_RESULT_BACKEND = 'redis://localhost/1' ) |
Definujemy tutaj tzw. brokera którego Celery będzie używać do kolejkowania i odbierania tasków jak i do zapisywania rezultatu. Ja mam Redisa – to taka przyjemna baza noSqlowa. Prosta w instalacji więc nie będę tu nic przeklejał. Nie będziemy tam zaglądać zbytnio ;)
Poza tym mamy jeszcze format danych ustawiony na json – nic ciekawego, chodzi o to w jakim formacie Celery będzie spodziewać się tasków jak i w jakim formacie je zapisywać. Jak widzicie nie muszą to być te same formaty.
CELERYD_CONCURRENCY jest o tyle ciekawe że określa ile workerów ma być uruchomionych a więc ile zadań może być jednocześnie przetwarzane.
Zakładam teraz iż pliki będziemy zapisywać w folderze:
1 | /var/www/html/htdocs/finished/ |
A więc sam kod Taska może być taki:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | from celery import Celery app = Celery('tasks', broker='redis://localhost/1') app.conf.update( CELERY_ACCEPT_CONTENT=['json'], CELERY_TASK_SERIALIZER='json', CELERYD_CONCURRENCY = 3, CELERY_RESULT_SERIALIZER='json', CELERY_RESULT_BACKEND = 'redis://localhost/1' ) @app.task() def convert(input_file_name, out_file_name): out = "/var/www/html/htdocs/finished/" + out_file_name print ("Out will be:"+out) command = "/usr/local/bin/HandBrakeCLI -i {0} -o {1}.mp4 -e x264 -q 22 -r 15 -B 96 -O".format(input_file_name, out) process = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE) output = process.communicate()[0] process.wait() return process.returncode |
Zainstalowałem sobie lighttpd i dołączyłem do niego (fastcgi) php’a 5.6. Stworzyć formularz HTMLa który może wgrywać pliki uważam że umiecie a jak nie umiecie to Internet umie ;) No i do tego kawałek PHPa którzy przesunie wgrany plik do folderu
1 | /var/www/html/htdocs/uploads/ |
Moglibyśmy z tego miejsca już dodać task do Celery – ale takie podejście nie do końca jest zgodne z mikroserwisami. My użyjemy modułu Python’a – watchdoga’a. Potrafi on nasłuchiwać na eventy filesystem’owe typu stworzenie pliku. I dokładnie na taki event będziemy nasłuchiwać – a task do Celery dodamy gdy taki event nadejdzie. Takie podejście pozwoli nam na łatwe kontrolowanie tego co jest wysyłane do Celery (logi watchdoga) no i na szybkie wyłączenie dodawania kolejnych tasków jeśli np. coś się wysypie.
A więc:
1 | pip install watchdog |
I kawałek kodu:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | #!/usr/local/bin/python3.3 import sys import time import logging from watchdog.observers import Observer from watchdog.events import FileSystemEventHandler from converters import convert import random, string class FileCreated(FileSystemEventHandler): def on_created(self, event): print (event.src_path) convert (event.src_path, ''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(7))); if __name__ == "__main__": path = sys.argv[1] if len(sys.argv) > 1 else '.' event_handler = FileCreated() observer = Observer() observer.schedule(event_handler, path, recursive=True) observer.start() try: while True: time.sleep(1) except KeyboardInterrupt: observer.stop() observer.join() |
Średnio jest tu co opisywać.. W on_created po prostu piszemy na stdout ścieżkę do pliku który idzie do Celery i delegujemy do niej taska z losową nazwą dla przekonwertowanego pliku. Przyda się wpis do supervisora (nie wiesz co to – przeczytaj):
1 2 3 4 5 | [program:watch_dog] command=/opt/virtual_envs/bin/python /root/wd/wd.py /var/www/html/htdocs/uploads/ user=root stdout_logfile=/var/log/watch_dog.log stderr_logfile=/var/log/watch_dog.log |
Jako argument przekazujemy folder na który ma nasłuchiwać ;)
Skoro jesteśmy przy supervisorze to jeszcze kawałek do niego dla Celery:
1 2 3 4 5 6 | [program:tasks] command=/opt/virtual_envs/bin/celery --app=converters worker --loglevel=info user=root environment=C_FORCE_ROOT="yes" stdout_logfile=/var/log/tasks.log stderr_logfile=/var/log/tasks.log |
No i teraz po wgraniu pliku watchdog to wykryje i wyśle taska do Celery a Celery wykona HandBrakeCLI i zwróci rezultat.
No i niby można by skończyć ale.. Przydałoby się jakoś efekt przesłać do użytkownika :P
A więc napiszemy do tego jeszcze malutki serwerek TCP w nodejs – a co tam, trochę urozmaicić language stack warto ;)
Plik package.json (odpowiednik setup.py):
1 2 3 4 5 6 7 8 9 10 11 12 13 | { "name": "ConvertersSocketServer", "version": "0.0.1", "description": "", "main": "index.js", "scripts": { "test": "echo "Error: no test specified" && exit 1" }, "author": "Mateusz Mazurek", "license": "BSD", "dependencies": { } } |
I kodzik:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | var net = require('net'); var clients = []; net.createServer(function (socket) { socket.stamp = Date.now(); function resendToClients(message) { filteredClients = []; clients.forEach(function (client, index) { if (client.writable) { client.write(message); filteredClients.push(client); console.log("Wysylam do klienta.") } }); console.log("===") clients = filteredClients; } socket.on('end', function () { if(!socket.deleted) clients.splice(clients.indexOf(socket), 1); }); clients.push(socket); socket.setEncoding('utf8'); socket.on('data', function (data) { try{ JSON.parse(data); clients.splice(clients.indexOf(socket), 1); console.log("Odebrano:"); console.log(data); socket.deleted = true; resendToClients(data); }catch(x){ //ignore } }); }).listen(8080); |
Serwer jest baardzo prosty. Czeka na dane i rozsyła je do pozostałych klientów. I tylko tyle robi ;)
W funkcji resendToClients wysyłamy odebrane dane do klientów którzy są w clients. Przy okazji filtrujemy rozłączonych/niedostępnych. Jeśli natomiast przyjdą dane ( socket.on(’data’), function) ) to pierw usuwamy klienta z clients – nie chcemy do nadawcy nic wysyłać – tutaj był race condition – co jakiś czas podczas odsyłania do niego wiadomości ten zrobił close() i node się wywalał – a skoro nie ma sensu mu nic wysyłać, to załatwiłem to własnie w taki sposób. Ten try{} pozwala nam ignorować wszystko co nie jest poprawnym jsonem – jeśli przyjdzie coś co nie jest jsonem to JSON.parse(data) wyrzuci wyjątek który.. Ignorujemy w catch{}. A jeśli jest poprawnym json’em to wykonywane jest, już wcześniej wspomniane resendToClients.
Nasze maleństwo działa na porcie 8080. ,
Do niego również wpis do supervisora:
1 2 3 4 5 | [program:node_js_tcp_srv] command=node /root/npm/index.js user=root stdout_logfile=/var/log/node_js_tcp_srv.log stderr_logfile=/var/log/node_js_tcp_srv.log |
Tak wiem że node ma swoją pm2kę ale po co mi ona skoro mam supervisora.. ? ;P
Teraz wypadałoby rozbudować naszego taska żeby wysyłał informację o tym że task się rozpoczął lub zakończył. Celery zapisuje ten wynik do Redisa i w sumie moglibyśmy z tego korzystać, ale on zapisuje to w kluczach a nie w kanałach (publish/subscribe) co moim zdaniem jest hiper niewygodne.
A wracając do taska dodajmy sobie do niego nieco configa:
1 2 | TCP_IP = '127.0.0.1' TCP_PORT = 8080 |
i funkcję która będzie nam wysyłać dane na nasz socket:
1 2 3 4 5 | def send_by_tcp(dict): s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((TCP_IP, TCP_PORT)) s.send(bytes(dumps(dict), 'UTF-8')) s.close() |
Poza tym żeby nie psuć naszego taska napiszmy prosty dekorator do niego:
1 2 3 4 5 6 7 8 9 10 11 12 | def send_notification(func): def inner(input_file_name, out_file_name): start_data = { "type": "start", "input": input_file_name, "output": out_file_name } send_by_tcp(start_data) retval = func.delay(input_file_name,out_file_name) return retval return inner |
i dodajmy
1 | @send_notification |
nad nasz task :)
Mamy więc już moment kiedy task jest dodawany do kolejki. Teraz przydałoby się wysłać coś jak się zakończy. Tutaj nie będzie już tak łatwo gdyż należy skorzystać z „mechanizmów” Celery a dokładnie przeciążyć metodę on_success:
1 2 3 4 5 6 7 8 9 10 11 | class DebugTask(Task): abstract = True def on_success(self, retval, task_id, args, kwargs): end_data = { "type": "end", "result": retval, "input": args[0], "output": args[1] } send_by_tcp(end_data) |
i kazać Celery korzystać z naszej klasy zmieniając @app.task na @app.task(base=DebugTask). Całość wygląda tak:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 | from celery import Celery, Task import subprocess import socket import time from json import dumps app = Celery('tasks', broker='redis://localhost/1') TCP_IP = '127.0.0.1' TCP_PORT = 8080 app.conf.update( CELERY_ACCEPT_CONTENT=['json'], CELERY_TASK_SERIALIZER='json', CELERYD_CONCURRENCY = 3, CELERY_RESULT_SERIALIZER='json', CELERY_RESULT_BACKEND = 'redis://localhost/1' ) def send_by_tcp(dict): s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((TCP_IP, TCP_PORT)) s.send(bytes(dumps(dict), 'UTF-8')) s.close() class DebugTask(Task): abstract = True def on_success(self, retval, task_id, args, kwargs): end_data = { "type": "end", "result": retval, "input": args[0], "output": args[1] } send_by_tcp(end_data) def send_notification(func): def inner(input_file_name, out_file_name): start_data = { "type": "start", "input": input_file_name, "output": out_file_name } send_by_tcp(start_data) retval = func.delay(input_file_name,out_file_name) return retval return inner @send_notification @app.task(base=DebugTask) def convert(input_file_name, out_file_name): out = "/var/www/html/htdocs/finished/" + out_file_name print ("Out will be:"+out) command = "/usr/local/bin/HandBrakeCLI -i {0} -o {1}.mp4 -e x264 -q 22 -r 15 -B 96 -O".format(input_file_name, out) process = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE) output = process.communicate()[0] process.wait() return process.returncode |
Teraz napotykamy na problem. Otóż naszą intencja było aby strona www gdzie użytkownik czeka na konwersję odbierała to co wysyła Celery (a dokładnie to co wysyła Node gdy już odbierze od Celery). Niestety pure TCP nie jest tym samym co WebSocket’y. Można powiedzieć że WebSocket’y to protokół nad TCP. Więc gdy chcielibyśmy z naszym serwerem połączyć się z przeglądarki to nawet by się udało, ale nic nie odbierzemy z niego ani nie wyślemy…
Na szczęście jest projekt zwany websockify. Pozwala on na proxowanie pure TCP <-> websocket. Udostępnia on serwer websocketowy który ma pod sobą nasz serwerek nodejs’ow. Użycie jest dość automagiczne. Ale pierw instalacja:
1 | pip install websockify |
Tak też mnie zdziwiło że jest w Pythonie napisany.
No i użycie:
1 | websockify 8181 localhost:8080 |
Tworzy on na porcie 8181 serwer websocketów którzy będzie przekierowywany na localhost:8080 – czyli na nasz nodejsowy serwerek. Rozwiązanie fajne bo na 8080 nadal możemy pisać a na 8181 przeglądarka może odbierać ;)
Przeróbmy nieco więc nasze PHPy. Niech PHP przekierowuje na stronę np:
1 | header('location:loading.php?file='.$_FILES["fileToUpload"]["name"]); |
A nasz loading.php może wyglądać tak:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | <!DOCTYPE html> <html> <style type="text/css"> img{ position: absolute; margin: auto; top: 0; left: 0; right: 0; bottom: 0; } </style> <body> <img src="large-ajax-loader.gif"/> </body> <script type="text/javascript"> var socket = new WebSocket("ws://adres:8181","base64"); socket.onmessage = function (event) { var data = JSON.parse(atob(event.data)); if(data['type'] == "end"){ if(data['result'] != 0){ alert("Blad, nie udalo sie skonwertowac pliku! Moze zly typ? Typie?!"); window.location.replace("/"); } else { var baseFilePath = data['input'].split("/"); var baseFileName = baseFilePath[baseFilePath.length -1]; if(baseFileName == '<?=$_GET['file']?>'){ window.location.replace("/result.php?file="+data['output']); } } } } </script> </html> |
Czyli wyświetlamy ładujący się GIF a w tle podłączając się do websocketu oczekujemy na dane które będą JSONem (zakodowanym w base64) o typie „start” i inpucie takim jak wgrywany przez osobę plik. I jeśli takie dane nadejdą to przekierowujemy na /result.php?file=”+data[’output’] i tam już proste i łatwe:
1 2 3 4 5 6 7 8 9 10 11 | <!DOCTYPE html> <html> <body> <video width="400" controls> <source src="finished/<?=$_GET['file']?>.mp4" type="video/mp4"> Your browser does not support HTML5 video. </video> </body> </html> |
Jeszcze kawałek z naszym proxy do supervisora dodamy:
1 2 3 4 5 | [program:websocket_proxy] command=/opt/run_websocket_proxy user=root stdout_logfile=/var/log/websocket_proxy.log stderr_logfile=/var/log/websocket_proxy.log |
A więc nasza architektura wygląda tak:

Hmm, nie jest maleńka, więc warto pomyśleć o monitorowaniu jej. Mamy oczywiście sporo logów i one pewnie by nam wystarczyły, ale istnieje coś takiego jeszcze jak Celery Flower – minitoring do Celery – też napisany w Pytonie. Uruchamiany poprzez:
1 | /opt/virtual_envs/bin/celery flower -A converters --address=0.0.0.0 --port=5555 |
Kilka zrzutów z ekranu:
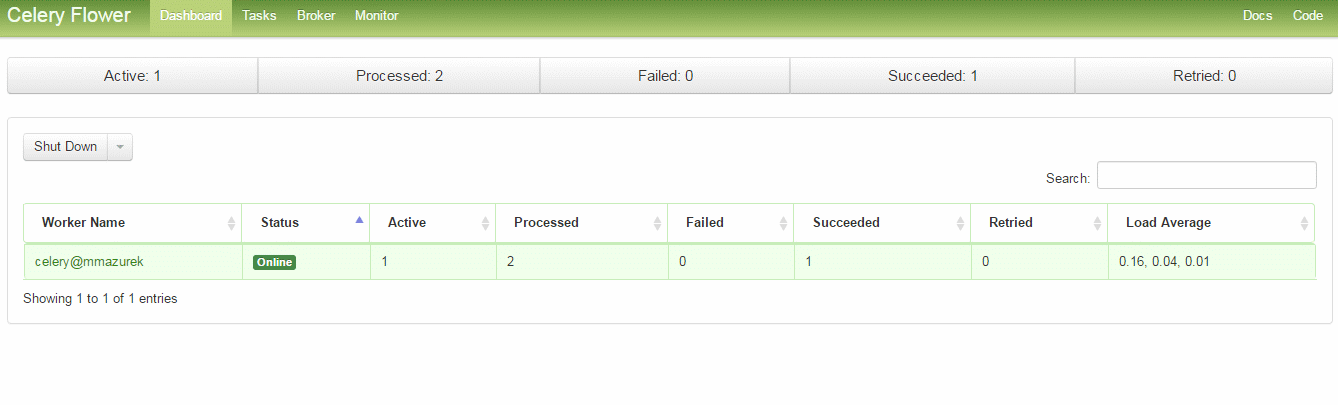

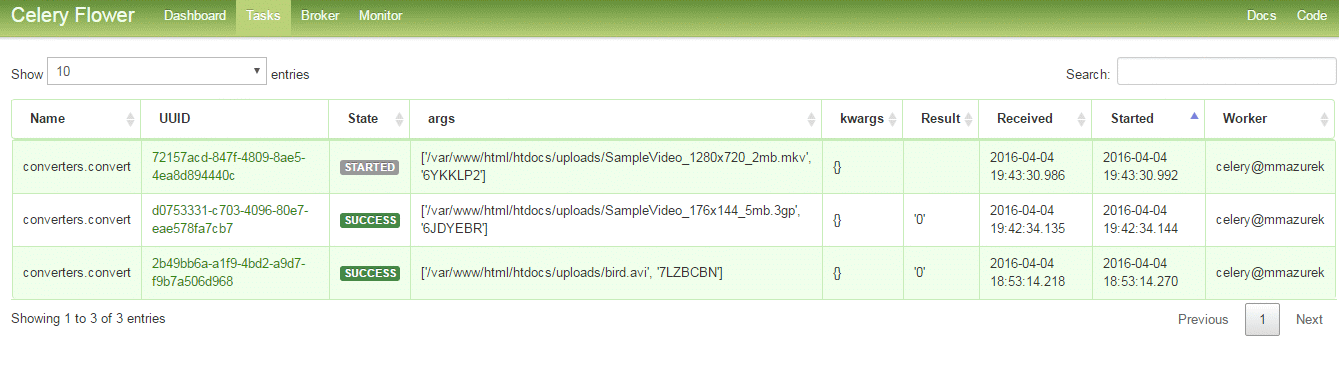
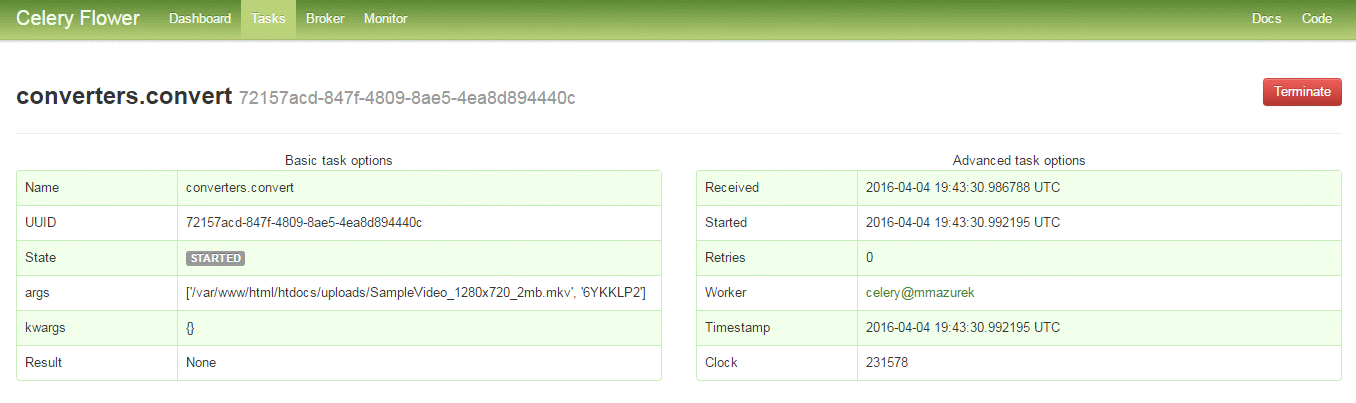
Poza tym skoro wiemy że Celery zapisuje sobie wszystko w Redisie to możemy skorzystać z redis-commandera – webowego klienta do Redisa. Niestety on średnio radzi sobie z dużą ilością kluczy. Alternatywą może być redis-futon, możemy w nim podglądać statystyki, dane i oczywiście korzystać z interaktywnej konsolki, screeny:
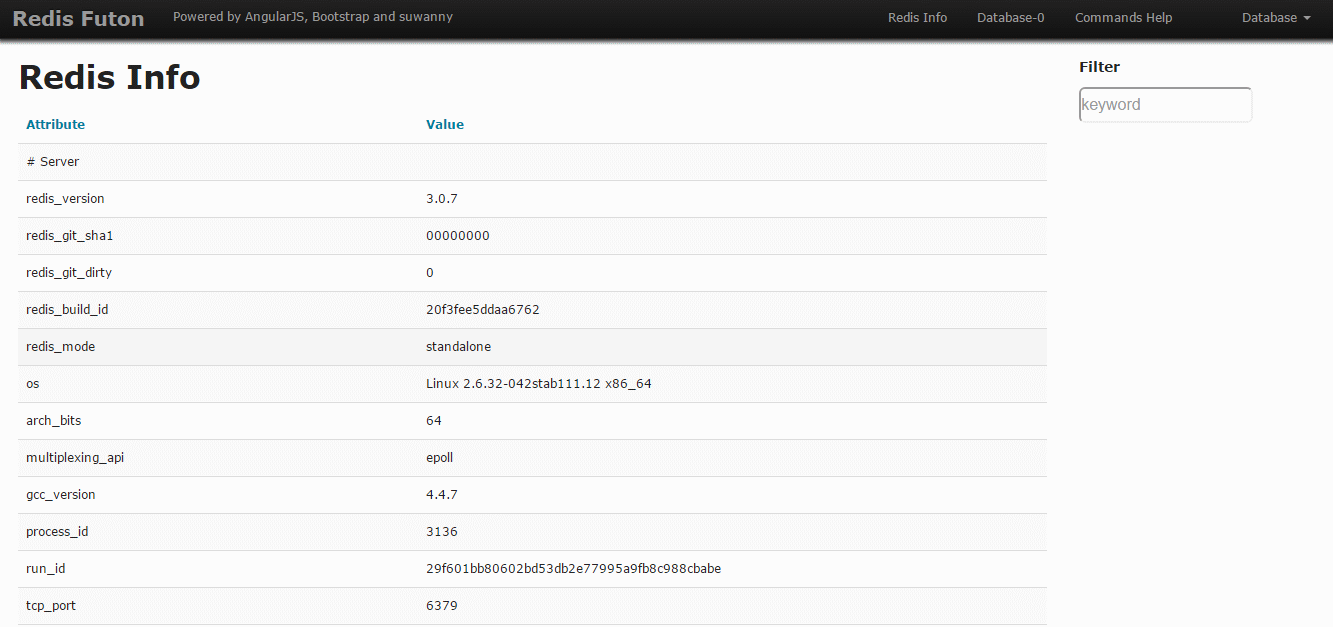
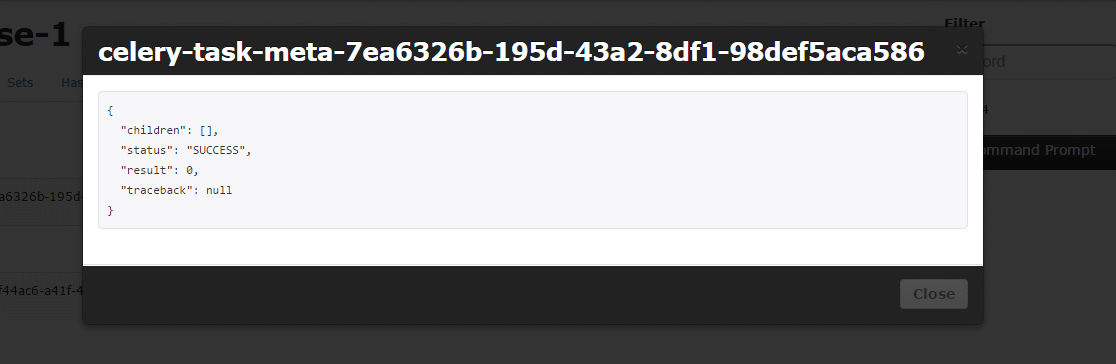
Widać na nich klucze Celery o których pisałem wcześniej. Tam jest przechowywany rezultat przetwarzania zadania.
No i byłoby to na tyle.
Mateusz Mazurek


