

Podgląd i zmiana wartości zmiennych in runtime – Python
Cześć,
jak pisałem we wcześniejszym wpisie, różne zdarzenia życiowe spowodowały że nagle mam znacznie więcej czasu, więc dziś poopowiadam Wam o ciekawym libie Python’owym – manhole. Z angielskiego manhole znaczy.. Właz. Kanalizacyjny. Taki jak mijacie na ulicach. A co on robi w Pythonie? Ano zgodnie z tytułem wpisu – pozwala wejść do programu w sposób interaktywny trochę tak „z boku”.
Ale powoli, napiszmy kawałek kodu który będzie agregował jakieś dane w pamięci. Niech ten program w odpowiedzi na wysyłanie do niego komunikatów wykonuje operacje które znajdują się w tym komunikacie. Uprośćmy to maksymalnie – komunikaty będą kazały wykonywać jedną z podstawowych działań matematycznych z aktualną wartością w pamięci a wartością wysłaną w owym komunikacie. Brzmi zagmatwanie? Nieee, jest turbo proste.
Stwórzmy 3 pliki w takiej hierarchii:
data_store
__init__.py
subscriber
__init__.py
main.py
I plik w folderze data_store niech ma taką zawartość:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | import inspect myself = lambda: inspect.stack()[1][3] class DataStore(): def __init__(self): self.current_value = 0 self.history = [] def __add__(self, other): self.current_value = self.current_value + other self.history.append([ other, str(myself()) ]) def __mul__(self, other): self.current_value = self.current_value + other self.history.append([ other, str(myself()) ]) def __sub__(self, other): self.current_value = self.current_value - other self.history.append([ other, str(myself()) ]) def __div__(self, other): self.current_value = self.current_value / other self.history.append([ other, str(myself()) ]) def __str__(self): return str(self.current_value) data_store = DataStore() |
Nic skomplikowanego – klasa definiuje zachowania operatorów dodawania, odejmowania, mnożenia i dzielenia jako operacje na jednej z zmiennych tej klasy i zapisuje te zmiany jako historię.
Teraz plik w folderze subscriber:
1 2 3 4 5 6 7 8 9 | import redis def main(worker): redis_conn = redis.Redis() subscriber = redis_conn.pubsub() subscriber.subscribe('test') for item in subscriber.listen(): worker(item['data']) |
Co tu robimy? Prawie nic. Na każdą wiadomość która przyjdzie na kanał redisowy o nazwe „test” reagujemy wykonując przekazaną w parametrze funkcję. Banalne, nie?
I na koniec plik main.py:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | from subscriber import main from datastore import data_store import operator from json import loads def worker(data): try: data = loads(data) print data op_func = getattr(operator, data['operation']) op_func(data_store, data['value']) except: pass if name == 'main': main(worker) |
Jako funkcję wejściową wykonujemy funkcję ze subscriber’a i przekazując mu jako argument naszą funkcję. Jaki będzie efekt? Bardzo prosty:
Jeśli na kanał wrzucimy 3 razy coś takiego:
redis-cli publish test '{"operation": "add", "value":6}'
To funkcja „worker” pobierze metodę dodającą i wykona na aktualnej wartości przechowywanej w data storze tę metodę. Co przy pierwszym wysłaniu spowoduje dodanie do 0 liczby 6. Drugie – do liczby 6 kolejną 6. I trzecie – do liczby 12(sumy) – kolejną 6. Co powoduje przechowanie w pamięci liczby 18 i 3 elementowej listy z historią tych operacji.
I teraz, na białym koniu, cały na biało – wjeżdża manhole.
Bo co jeśli w kodzie jest np. błąd i wartość przechowywana w pamięci jest zepsuta? Oczywiście można logować każdą zmianę i w myśl event source’ingu – odtworzyć stan i tak go skorygować dodatkowymi komunikatami by był poprawny, ale raz że to dość pracochłonne zajęcie a dwa wymusza wyczyszczenie pamięci programu co może wiązać się różnymi konsekwencjami. Np. straceniem tych danych które są poprawne lub przerwę w działaniu usługi.
Zmodyfikujmy więc nasz kod troszkę:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | from subscriber import main from datastore import data_store import operator from json import loads import manhole def worker(data): if data == 'enable_manhole': manhole.install(locals={'data_store':data_store}) else: try: data = loads(data) print data op_func = getattr(operator, data['operation']) op_func(data_store, data['value']) except: pass if __name__ == '__main__': main(worker) |
Dodaliśmy tu obsługę „zainstalowania” naszego włazu programistycznego. Wiec sprawdźmy to! Wyślijmy:
redis-cli publish test 'enable_manhole'
co spowoduje wypisanie na standardowe wyjście naszego programu:
Manhole[17744:1524079049.5979]: Patched <built-in function fork> and <built-in function fork>.
Manhole[17744:1524079049.5988]: Manhole UDS path: /tmp/manhole-17744
Manhole[17744:1524079049.5988]: Waiting for new connection (in pid:17744) ...
Co znaczy że manhole się zainstalował w osobnym wątku i udostępnia dostęp do programu (a dokładniej do zmiennej data_store co jest zdefiniowane parametrem locals) jako socket unixowy pod ścieżką /tmp/manhole-17744.
Połączmy się!
sudo nc -U /tmp/manhole-17744
Co spowoduje info o przyjęciu połączenia:
Manhole[17744:1524079333.6725]: Started ManholeConnectionThread thread. Checking credentials …
Manhole[17744:1524079333.6726]: Accepted connection on fd:5 from PID:18093 UID:0 GID:0
a my mamy dostęp do programu w formie interaktywnej konsoli Pythona:
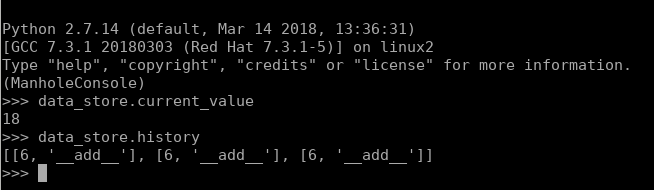
możemy też edytować zmienne:
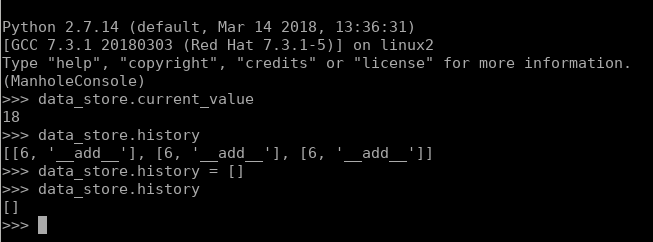
Wydaje mi się że łatwo zauważyć potencjał tej biblioteki.
Mateusz Mazurek



Ciekawy artykuł. Zdaje się, że koniecznie muszę nadrobić swoje zaległości jeśli chodzi o redisa, bo kiedy w przeszłości miałem okazję używać tej bazy, to nigdy nie bawiłem się w niej kanałami, a wyglądają one na zdecydowanie przydatną funkcjonalność. ;)