

Java, Kotlin, Scala – co łączy te trzy języki programowania? Rzecz o ekosystemie JVMa
No cześć,
na swojej ścieżce „kariery” zawodowej miałem przyjemność poznać sporo technologii. Chociaż, jakby się zastanowić, to słowo „poznać” jest lekkim nadużyciem, lepszym słowem byłoby „dotknąć” – tak czy siak, drepcząc radośnie ową ścieżką, miałem przyjemność przez jakiś czas spacerować w towarzystwie Javy. Dziś więc trochę o niej i o językach które maja z Javą pewną cechę wspólną.
Żeby zrozumieć to co chcę pokazać, muszę się trochę cofnąć względem głównego tematu. No więc zacznijmy od pre-początku:)
Jak uruchamiane są programy Javowe?
W pewnym uproszczeniu wygląda to tak:
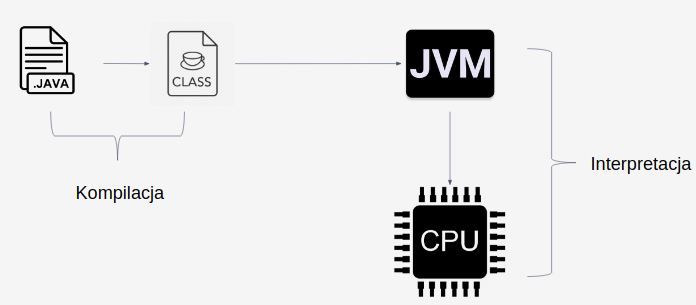
I co, wygląda to trochę inaczej niż włączenie IntelliJ’a, napisanie programu i kliknięcie zielonego przycisku, który jeszcze jakiś czas temu kojarzył się ze słowem „play”, nie?
Wszystko zaczynam się podobnie jak w IDE – od napisania programu i zapisaniu go do pliku *.java. Gdy plik ten jest gotowy to kompilator javy (javac) przygotuje dla nas plik wynikowy *.class.
Plik ten jest natomiast przekazywany do JVM’a (Java Virtual Machine) czyli maszyny wirtualnej Javy. Tam przebiega proces interpretacji, wspomagany technologią JIT, dzięki któremu do procesora trafia nasz program, już w formie zrozumiałej dla procesora a więc, na najniższym poziomie abstrakcji, w formie kodu maszynowego.
Czym jest plik *.class
Zatrzymajmy się na chwilę przy plikach *.class – pliki te to binarny zapis kodu pośredniego – kodu który jest pomiędzy tym co My piszemy w Javie i tym, co procesor dostaje do przetworzenia. Pisząc „pomiędzy” mam na myśli że jest to taki półprodukt procesu uruchamiania programu Javowego.
Takie rozwiązanie pozwala Javie na to by programy pisane w niej były kompilowane raz a skompilowany kod był przenośmy pomiędzy systemami i architekturami. Jest to efekt tego że po prostu ten kod nie ma prawa działać na żadnym procesorze. Więc nie musi być JESZCZE zgodny z docelową architekturą.
By skompilowany kod uruchomić, potrzebujemy zainstalować JRE – Java Runtime Environment – czyli zestaw narzędzi niezbędnych do obsługi programów napisanych w Javie. Jednym ze składowych tego zestawu jest właśnie JVM.
JRE jest niewystarczające jeśli chcemy tworzyć programy w Javie – żeby móc to robić należy zainstalować JDK – Java Development Kit który zawiera już w sobie JRE. I ma to oczywiście logiczny sens.
Jak wygląda kod pośredni?
Bytecode, bo i tak się mówi na kod pośredni, możemy sobie wygenerować. Napiszmy prosty program w Javie:
1 2 3 4 5 6 7 8 9 10 11 12 13 | package pl.flomedia; public class Main { public static void main(String[] args) { int a = 15; int b = 20; int sum = a + b; System.out.println(sum); } } |
Nooo, wzbiliśmy się tu na wyżyny umiejętności co najmniej kilkuletniego seniora :)
Wynik tego kunsztu developerskiego to oczywiście 35.
No i teraz w konsoli pierw generujemy plik *.class:
javac pl/flomedia/Main.java
oczywiście z folderu przed namespace’em. I teraz na pliku Main.class użyjemy deassemblera:
javap -v pl/flomedia/Main.class > bytecode.s
co spowoduje przekierowanie standardowego wyjścia polecenia javap do pliku bytecode.s który dla wyżej napisanego programu wygląda tak:
Classfile /home/mmazurek/IdeaProjects/Blaog1/src/pl/flomedia/Main.class
Last modified 2019-02-26; size 412 bytes
MD5 checksum 4e6b585d05de2b6be8767a63d8ac08e3
Compiled from "Main.java"
public class pl.flomedia.Main
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Methodref #5.#14 // java/lang/Object."<init>":()V
#2 = Fieldref #15.#16 // java/lang/System.out:Ljava/io/PrintStream;
#3 = Methodref #17.#18 // java/io/PrintStream.println:(I)V
#4 = Class #19 // pl/flomedia/Main
#5 = Class #20 // java/lang/Object
#6 = Utf8 <init>
#7 = Utf8 ()V
#8 = Utf8 Code
#9 = Utf8 LineNumberTable
#10 = Utf8 main
#11 = Utf8 ([Ljava/lang/String;)V
#12 = Utf8 SourceFile
#13 = Utf8 Main.java
#14 = NameAndType #6:#7 // "<init>":()V
#15 = Class #21 // java/lang/System
#16 = NameAndType #22:#23 // out:Ljava/io/PrintStream;
#17 = Class #24 // java/io/PrintStream
#18 = NameAndType #25:#26 // println:(I)V
#19 = Utf8 pl/flomedia/Main
#20 = Utf8 java/lang/Object
#21 = Utf8 java/lang/System
#22 = Utf8 out
#23 = Utf8 Ljava/io/PrintStream;
#24 = Utf8 java/io/PrintStream
#25 = Utf8 println
#26 = Utf8 (I)V
{
public pl.flomedia.Main();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: bipush 15
2: istore_1
3: bipush 20
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
13: iload_3
14: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
17: return
LineNumberTable:
line 6: 0
line 7: 3
line 9: 6
line 11: 10
line 12: 17
}
SourceFile: "Main.java"
Pierwsze 5 linijek jest pewnie jasnych, dalej mamy:
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Co oznacza wersję Javy i może przyjmować wartości
- Java SE 10 = 54 (0x36 hex)
- Java SE 9 = 53 (0x35 hex)
- Java SE 8 = 52 (0x34 hex)
- Java SE 7 = 51 (0x33 hex)
- Java SE 6.0 = 50 (0x32 hex)
a mniejsze numery to oczywiście – wcześniejsze wersje Javy. Flagi to po prostu flagi jakie są używane w tej klasie.
Dalej mamy Constant Pool – czyli sekcję która przechowuje informacje o stałych używanych w programie a niże to już czysty bytecode:
{
public pl.flomedia.Main();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: bipush 15
2: istore_1
3: bipush 20
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
13: iload_3
14: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
17: return
LineNumberTable:
line 6: 0
line 7: 3
line 9: 6
line 11: 10
line 12: 17
}
Zanim sobie w niego zerkniemy, czuję że warto przypomnieć jak działa struktura danych zwana stosem.
Stos to bufor „pracujący w trybie” Last In, First Out – czyli ten element który ostatnio został odłożony, zostanie jako pierwszy pobrany. Trochę jak ze stosem książek – żeby dobrać się do którejś, trzeba zdjąć wszystkie które są na niej.
Z ciekawostek to warto wspomnieć o tym że logo stackoverflow przedstawia stos
który się po prostu przepełnił;)
Czekaj, stop!
Podoba Ci się to co tworzę? Jeśli tak to zapraszam Cię do zapisania się na newsletter:Jeśli to Cię interesuje to zapraszam również na swoje social media.
Jak i do ewentualnego postawienia mi kawy :)

Ale wracając do kodu pośredniego – zerknijmy na niego sobie.
public pl.flomedia.Main();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
czyli konstruktor klasy Main który robi tylko tyle że woła konstruktor klasy Object. Dalej mamy naszego main’a:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1
0: bipush 15
2: istore_1
3: bipush 20
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
13: iload_3
14: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
17: return
LineNumberTable:
line 6: 0
line 7: 3
line 9: 6
line 11: 10
line 12: 17
I kawałek z kodem wraz z tłumaczeniem:
0: bipush 15 // odłóż na stos liczbę 15
2: istore_1 // weź wartość ze stosu (15) i zapisz do zmiennej nr 1
3: bipush 20 // odłóż na stos liczbę 20
5: istore_2 // weź wartość ze stosu (20) i zapisz do zmiennej nr 2
6: iload_1 // weź wartość zmiennej nr 1 i odłóż na stos
7: iload_2 // weź wartość zmiennej nr 2 i odłóż na stos
8: iadd // dodaj dwie wartości z wierzchołka stosu i umieść na nim wynik
9: istore_3 // zapisz do zmiennej nr 3 wartość z wierzchołka stosu
10: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream; - odłóż ten obiekt na stos
13: iload_3 // odłóż wartość zmiennej nr 3 (35) na stos
14: invokevirtual #3 // Method java/io/PrintStream.println:(I)V - wykonaj metodę a jako argument weź element ze stosu
17: return // zakończ
Czym jest wcześniej wspomniany JIT?
Ten temat jest akurat mega ciekawy.
Jak już wcześniej sobie powiedzieliśmy – etap pomiędzy plikiem *.class a działającym kodem jest realizowany za pomocą techniki zwanej interpretacją, która jest wspomagana technologią JIT.
Interpretacja to mechanizm w którym nasz kod jest wykonywany linijka po linijce, sposób ten jest z definicji wolniejszy od kompilacji, co dało pole do popisu w kwestii optymalizacji.
No i taką właśnie optymalizacją jest JIT (just-in-time compiler).
JIT to pomysł na kompilację fragmentów kodu które są często wykonywane.
W celu wyboru którą metodą warto skompilować, nasz kod, podczas wykonywania jest na bieżąco analizowany i to właśnie statystyka naszego kodu odpowiada którego jest miejsca są „gorące” – czyli często używane i te stara się kompilować.
Ale to dopiero czubek góry! Ponieważ JIT nie tylko kompiluje fragmenty ale przed kompilacją je optymalizuje co daje w efekcie turbo ciekawe efekty. Ale bez pustego gadania, zerknijmy na przykład:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | public class Main { public static void checkValidation(Object o){ if (o == null){ System.out.println("Object is NOT valid!"); } } public void checkRules(){ checkValidation(this); } public static void main(String[] args) { Main m = new Main(); m.checkRules(); } } |
Sądzę że w przypadku tego kodu, wnikliwy obserwator, łatwo zauważy że coś tu jest bez sensu, ale zostawmy to na razie, przyjrzyjmy się bliżej temu kawałkowi
1 2 3 4 5 6 7 8 9 | public static void checkValidation(Object o){ if (o == null){ System.out.println("Object is NOT valid!"); } } public void checkRules(){ checkValidation(this); } |
JIT analizując sobie nasz kod uznał że metodę checkRules trzeba skompilować. Przed tym jednak zaczął ją optymalizować.
Pierwszą, podstawową optymalizacją jest „zagnieżdżanie metod” czyli inline’ing i polega on na zastępowaniu wywołania metody jej ciałem, oczywiście tam gdzie można. I tu efekt jest taki:
1 2 3 4 5 6 7 8 9 10 11 | public static void checkValidation(Object o){ if (o == null){ System.out.println("Object is NOT valid!"); } } public void checkRules(){ if (this == null){ System.out.println("Object is NOT valid!"); } } |
Po prostu wywołanie zamieniliśmy na definicję i w warunku podmieniliśmy parametr na this’a.
Kolejna optymalizacja sprawdzi nam warunek – skoro porównujemy this’a z nullem to przecież to nigdy nie może być prawdą, więc zachodzi optymalizacja i kod wygląda tak:
1 2 3 4 5 6 7 8 9 10 11 | public static void checkValidation(Object o){ if (o == null){ System.out.println("Object is NOT valid!"); } } public void checkRules(){ if (false){ System.out.println("Object is NOT valid!"); } } |
No jak się domyślacie, teraz wejdzie optymalizacja usuwająca martwy kod, czyli taki który nigdy się nie wykona. Łatwo zobaczyć jaki będzie jej efekt na powyższym kodzie. Ale dla porządku, zerknijcie:
1 2 3 4 5 6 7 | public static void checkValidation(Object o){ if (o == null){ System.out.println("Object is NOT valid!"); } } public void checkRules(){ } |
Przyznaj proszę że niesamowite:)
Po więcej informacji zapraszam do wystąpienia Jarka:
Java, Kotlin, Scala – co je w końcu łączy?
No, wstęp był długi, ale za to jaki wartościowy!
No więc skoro to plik *.class są plikami które efektywnie są uruchamiane przez JVMa, to co stoi na przeszkodzie by to nie Java była językiem wyjściowym?
Z dokładnie tego samego pomysłu wyszli twórcy Kotlina i Scali. Ale żebym nie był gołosłowny, pobawmy się w poliglotę i napiszmy ten sam program dodający liczby w tych językach.
Kotlin pierwszy:
1 2 3 4 5 6 7 8 | fun main(args: Array<String>){ val a:Int = 20 val b:Int = 15 val sum:Int = a + b println(sum) } |
i w IntelliJ’u klikamy sobie w Tools -> Kotlin -> Show Bytecode i naszym oczom ukazuje się
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
BIPUSH 20
ISTORE 1
L2
LINENUMBER 4 L2
BIPUSH 15
ISTORE 2
L3
LINENUMBER 6 L3
ILOAD 1
ILOAD 2
IADD
ISTORE 3
L4
LINENUMBER 8 L4
L5
GETSTATIC java/lang/System.out : Ljava/io/PrintStream;
ILOAD 3
INVOKEVIRTUAL java/io/PrintStream.println (I)V
L6
L7
LINENUMBER 9 L7
RETURN
L8
Co jest dokładnie tym samym co w Javie! Ha!
Lecimy ze Scalą:
1 2 3 4 5 6 7 8 9 10 11 | object Main { def main(args: Array[String]): Unit = { var a: Int = 20 var b: Int = 15 var sum: Int = a + b println(sum) } } |
i jego kod pośredni:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ISTORE 2
BIPUSH 15
ISTORE 3
ILOAD 2
ILOAD 3
IADD
ISTORE 4
GETSTATIC scala/Predef$.MODULE$ : Lscala/Predef$;
ILOAD 4
INVOKESTATIC scala/runtime/BoxesRunTime.boxToInteger (I)Ljava/lang/Integer;
INVOKEVIRTUAL scala/Predef$.println (Ljava/lang/Object;)V
RETURN
MAXSTACK = 2
MAXLOCALS = 5
Tu już trochę ten kod się różni od Kotlina i Javy, chociażby tym że Kotlin korzysta z println’a Javowego a Scala nie, ale nie przeszkadza to w odnalezienie fragmentu bytecode’u podobnego do tego z Javy/Kotlina.
Do brzegu
Pisząc ten wpis chciałem pokazać przede wszystkim jak fajnym a jednocześnie jak bardzo skomplikowanym rozwiązaniem jest JVM a sam fakt że powstają języki oparte o tę technologię tylko to potwierdza.
Mateusz Mazurek



Bardzo fajny artykuł, od dłuższego czasu obserwuję Twój blog i można dowiedzieć się wiele ciekawych rzeczy ;) Pozdrawiam :)
Dzięki ogromne za krzepiące słowa! :) To wiele znaczy, serio:)