

Cześć, dawno tu nie pisałem. Sporo się zmieniło w moim życiu, ale we wpisie ograniczę się tylko do tego iż osiągnąłem wykształcenie wyższe magisteriskie – co jest już tytułem naukowym i w pełni mogę mówić o sobie „Pan magister inżynier” :D yeah!
Hm.. Jak się pewnie domyślacie zbyt dużo to w moim życiu nie zmieniło, no może poza tym że jestem jakieś 1000zł lżejszy ;) wiecie, rzeczy typu garnitu, druk pracy, opłaty itp – samo szczęście ;)
Aczkolwiek chce streścić co robiła moja praca magisteriska, gdyż „Przetwarzanie rozproszone danych strumieniowych z użyciem Apache Storm na platformie Amazon Web Services” brzmi dość skomplikowanie.
A więc… Chciałem stowrzyć dość generyczny system przetwarzania rozproszonego – a więc coś co można uruchomić na wielu komputerach i w ten sposób zwiększać wypadkową moc obliczeniową.
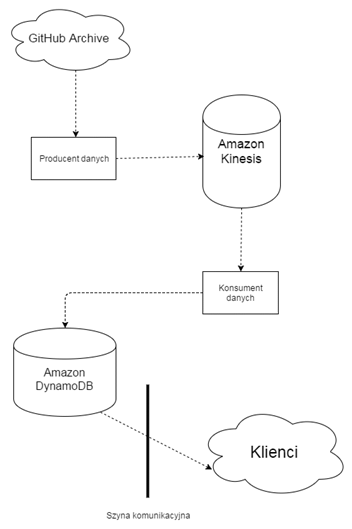
Rysunek 1 przedstawia architekturę – zaczynamy się od Producenta Danych – w przypadku mojej pracy jest to autorski program który strumienuje dane pochodzące z serwisu GitHub Archive – pobiea je i w odpowiednich porcjach traktuje jako strumień – taki strumień wlewany jest do Amazon Kinesis.

Usługa ta, jak widać na obrazku powyżej pozwala na strumieniowanie danych pochodzących od różnych klientów przy okazji zapewniając ograniczenia przepustowości, shard’owane oraz kilka innych feature’ów.
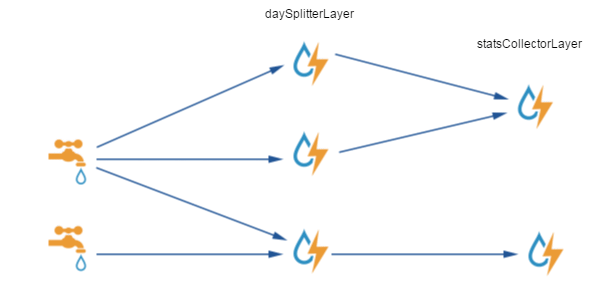
Do takiego strumienia podłącza się Konsument Danych – byt oparty o Apache Storm – open soure’owy system przetwarzania rozposzonego – który koryguje oraz nadzoruje cały proces. Topologia sieci przetwarzającej jest przedstwiona na rys 2. – gdzie mamy wydzielone dwie warstwy przetwarzania – warstwę daySplitter oraz statsCollector których nazw raczej nie muszę tłumaczyć oraz samego ich działania.
Przetwarzane w ten sposób dane, a dokładniej rezultat przetwarzania – bo celem była taka agregacja danych z GitHub Archive żeby uzyskać statystyki użytkowania GitHub’a w czasie rzeczywistym – czyli ciągle aktualną ilość commitów pushy itp. – zapisywane są w bazie DynamoDB – taka baza noSql’owa od Amazona.
Do tego wszystkiego jest napisane serwer websocketowy który pozwala klientom na pobieranie aktuanych danych z DynamoDB oraz ich wyświetlanie na ekranie w formie np. samoaktualizującego się wykresu.
Praca obroniona rzecz jasna na ocenę 5 ;)
Rózne zdarzenia spowodowały iż na razie przystopuję na wyżej wymienionym tytule naukowym ;)
Podsumowując moje 5 lat na uczelni – mimo że przeszkadzały w robieniu pieniędzy, czasem były bezsensowne to gdybym mógł cofnąć czas – poszedłbym na studia! Bardzo fajny czas, bardzo fajni ludzie, mimo wszystko sporo wiedzy, nie tylko informtycznej. A więc, „not forgeting about final part” – polecam Politechnikę Łódzką z czystym sumieniem.
No i.. Mam teraz więcej czasu więc pewnie coś napiszę tu nowego :)
Mateusz Mazurek



Tytułem naukowym nazywamy tytuł profesora (zwyczajnego lub nadzwyczajny), natomiast magister nadal jest tytułem zawodowym jak technik, inżynier czy licencjat…
Masz rację :)